Posts
2572Following
668Followers
1496buherator
buherator
https://blog.exploits.club/exploits-club-weekly-newsletter-87-nvidia-merlin-bugs-grapheneoss-allocator-intel-cpu-bugs-and-more/
 0
0
 0
0
 1
1
buherator
buheratorhttps://infosec.exchange/@david_chisnall/115270162462304611
0
0
0
repeated
Kevin Beaumont
GossiTheDog@cyberplace.socialFor those who haven't been following JLR in detail, key chain of events:
1) JLR outsource key IT and infosec functions to TCS, approved by 1x director and 2x NEDs on both JLR and TCS boards
2) JLR transfer staff by TUPE to TCS
3) TCS lay off transferred UK staff, including cyber risk and governance and cyber monitoring
4) record profits for a decade
5) got hacked
6) company stops functioning
7) get government to bail out their key suppliers (in progress)
3
6
0
repeated
David Chisnall (*Now with 50% more sarcasm!*)
david_chisnall@infosec.exchangeI think this needs to be repeated, since I tend to be quite negative about all of the 'AI' hype:
I am not opposed to machine learning. I used machine learning in my PhD and it was great. I built a system for predicting the next elements you'd want to fetch from disk or a remote server that didn't require knowledge of the algorithm that you were using for traversal and would learn patterns. This performed as well as a prefetcher that did have detailed knowledge of the algorithm that defined the access path. Modern branch predictors use neural networks. Machine learning is amazing if:
- The problem is too hard to write a rule-based system for or the requirements change sufficiently quickly that it isn't worth writing such a thing and,
- The value of a correct answer is much higher than the cost of an incorrect answer.
The second of these is really important. Most machine-learning systems will have errors (the exceptions are those where ML is really used for compression[1]). For prefetching, branch prediction, and so on, the cost of a wrong answer is very low, you just do a small amount of wasted work, but the benefit of a correct answer is huge: you don't sit idle for a long period. These are basically perfect use cases.
Similarly, face detection in a camera is great. If you can find faces and adjust the focal depth automatically to keep them in focus, you improve photos, and if you do it wrong then the person can tap on the bit of the photo they want to be in focus to adjust it, so even if you're right only 50% of the time, you're better than the baseline of right 0% of the time.
In some cases, you can bias the results. Maybe a false positive is very bad, but a false negative is fine. Spam filters (which have used machine learning for decades) fit here. Marking a real message as spam can be problematic because the recipient may miss something important, letting the occasional spam message through wastes a few seconds. Blocking a hundred spam messages a day is a huge productivity win. You can tune the probabilities to hit this kind of threshold. And you can't easily write a rule-based algorithm for spotting spam because spammers will adapt their behaviour.
Translating a menu is probably fine, the worst that can happen is that you get to eat something unexpected. Unless you have a specific food allergy, in which case you might die from a translation error.
And that's where I start to get really annoyed by a lot of the LLM hype. It's pushing machine-learning approaches into places where there are significant harms for sometimes giving the wrong answer. And it's doing so while trying to outsource the liability to the customers who are using these machines in ways in which they are advertised as working. It's great for translation! Unless a mistranslated word could kill a business deal or start a war. It's great for summarisation! Unless missing a key point could cost you a load of money. It's great for writing code! Unless a security vulnerability would cost you lost revenue or a copyright infringement lawsuit from having accidentally put something from the training set directly in your codebase in contravention of its license would kill your business. And so on. Lots of risks that are outsourced and liabilities that are passed directly to the user.
And that's ignoring all of the societal harms.
[1] My favourite of these is actually very old. The hyphenation algorithm in TeX trains short Markov chains on a corpus of words with ground truth for correct hyphenation. The result is a Markov chain that is correct on most words in the corpus and is much smaller than the corpus. The next step uses it to predict the correct breaking points in all of the words in the corpus and records the outliers. This gives you a generic algorithm that works across a load of languages and is guaranteed to be correct for all words in the training corpus and is mostly correct for others. English and American have completely different hyphenation rules for mostly the same set of words, and both end up with around 70 outliers that need to be in the special-case list in this approach. Writing a rule-based system for American is moderately easy, but for English is very hard. American breaks on syllable boundaries, which are fairly well defined, but English breaks on root words and some of those depend on which language we stole the word from.
10
21
0
repeated
Kevin Beaumont
GossiTheDog@cyberplace.socialRegulation works again - if you run Windows 10 in Europe, you will keep receiving extended security updates for free. No need to enable Windows Backup or jump through hoops. October 2025 isn't the end.
9
32
0
repeated
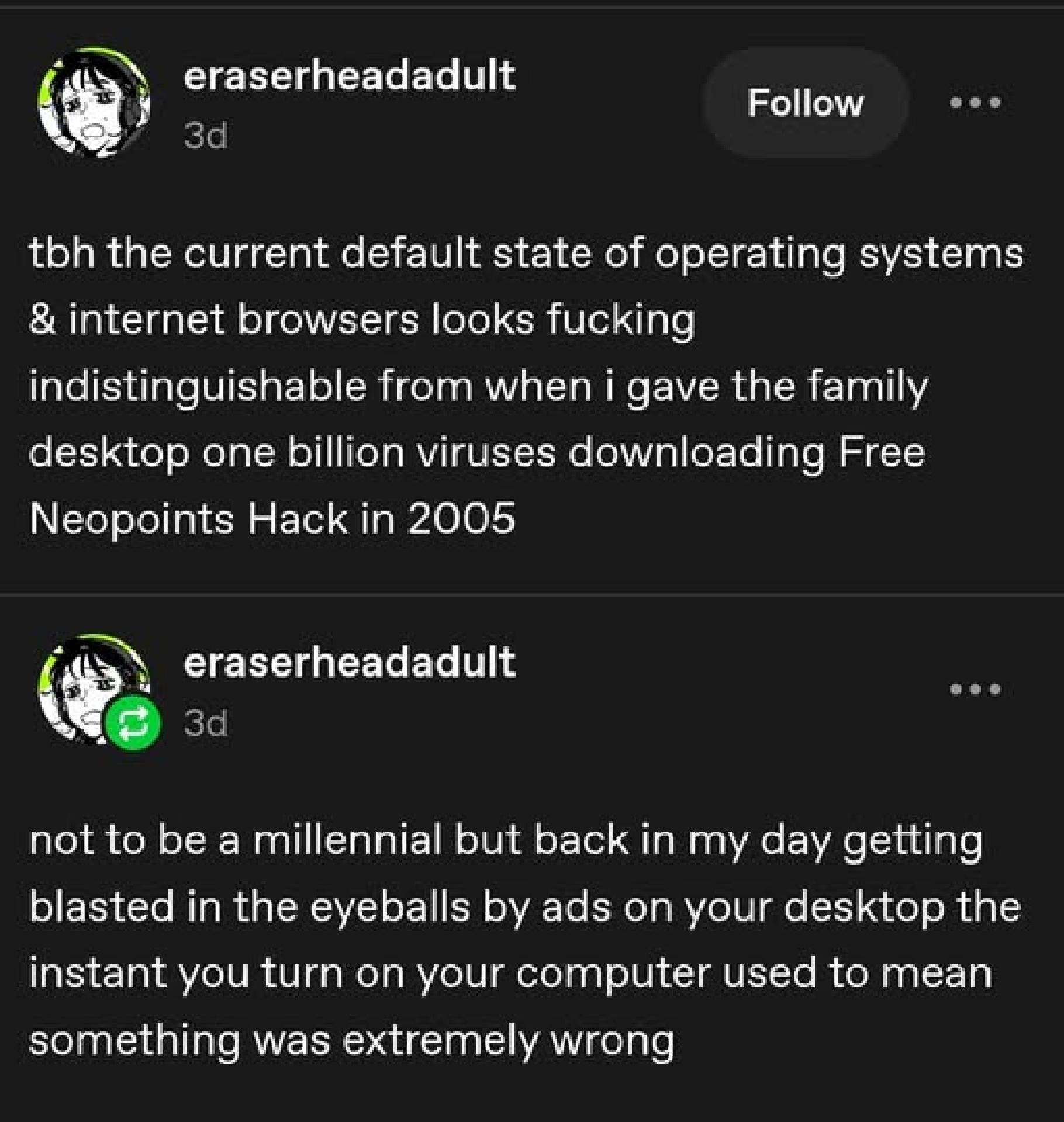
Sheepie
bastardsheep@aus.socialToo real.
Windows 11 out of the box experience is terrible and getting worse.
 7
18
1
repeated
7
18
1
repeated
Brewster Kahle
brewsterkahle@mastodon.archive.orgInternet Archive Europe progress: new network router is now installed in central switching point. Onward!
https://www.internetarchive.eu/
(Will substitute for one supported by XS4ALL and KPN for 20+ years -- thank you!)
 0
4
1
repeated
0
4
1
repeated
Lars Wirzenius
liw@toot.liw.fiOn this day in 1983 Stanislav Petrov saved the world by declining to start a nuclear war.
1
12
0
buherator
buheratorhttps://seclists.org/oss-sec/2025/q3/175
Interesting (and civil!) discussion on #Rowhammer
0
0
2
repeated
Caitlin Condon
catc0n@infosec.exchangePretty unfortunate update on Fortra GoAnywhere MFT CVE-2025-10035 from the folks at @watchtowrcyber. Yikes. https://labs.watchtowr.com/it-is-bad-exploitation-of-fortra-goanywhere-mft-cve-2025-10035-part-2/
0
3
0
buherator
buheratorhttps://www.linaro.org/blog/blog-2-posted-patches-what-next/
0
1
0
buherator
buheratorhttps://streypaws.github.io/posts/Fast-and-Faulty-A-Use-After-Free-in-KGSL-Fault-Handling/
#Qualcomm CVE-2024-38399
0
0
2
buherator
buheratorhttps://x41-dsec.de/security/research/news/2025/09/25/mouse-entropy/
0
2
3
repeated
Kevin Beaumont
GossiTheDog@cyberplace.socialThree new CVEs for Cisco AnyConnect/ASA
CVE-2025-20333
CVE-2025-20363
CVE-2025-20362
Chained and under active exploitation since earlier in the year
 3
4
0
3
4
0
buherator
buheratorhttps://blog.trailofbits.com/2025/09/25/taming-2500-compiler-warnings-with-codeql-an-openvpn2-case-study/
0
1
1
repeated
Rebane
rebane2001@infosec.exchangei can finally share the google docs attack poc from my slides!!
blogpost coming later
(video 1/2 - the attack)
1
2
0
repeated
rev.ng
revng@infosec.exchange🔴 We just published our Black Hat Arsenal talk (part 1)!
It's a brief tutorial on:
1. using rev.ng from the CLI;
2. playing around with the decompiled code in VSCode;
3. finding bugs with clang static analyzer! 🦾
1
2
0
repeated
nedwill
nedwilliamson@bird.makeup
I didn't know how to explain it at the time but we have words for my bug report now: I used the SSDP RFC -> LLM-generated EBNF grammar -> vibe-coded Rust compiler for EBNF to Protobuf -> vibe-coded C++ frontend -> vibe-coded root cause -> vibe-coded report https://issues.chromium.org/issues/40070891
1
1
0
repeated
Virus Bulletin
VirusBulletin@infosec.exchange🏆 VB2025 Péter Szőr Award — Finalists Announced!
We're excited to reveal the three shortlisted finalists for this year’s Péter Szőr Award, selected by committee vote
The winner will be announced at the Gala Dinner this evening, Thursday 25 September, at VB2025 in Berlin.
 0
2
0
0
2
0
