Posts
3900Following
728Followers
1601 repeated
repeated

 repeated
repeated
Lukasz Olejnik
LukaszOlejnik@mastodon.social87-year-old writes to Financial Times. This is a real technological problem also for people with disabilities. Including me. Banking systems (and others) may make people's life miserable. And you know what? In case of an issue, I couldn't even make a phone call (when mandatory).
 1
6
1
6
 0
repeated
0
repeated
Brandon Falk
gamozolabs@bird.makeup
Live now! Doing some Linux virtual memory manager experiments by using processes instead of threads! Maybe a custom allocator too! https://stream.bfa.lk/ . Also live on Twitch and YouTube :3
0
2
0
repeated
"Your personal information is very important to us."
Crowdsourcing snark! Dear Lazyweb,
Bbefore they will let me publish a new release of XScreenSaver on the "Play" [sic] store, Google, the most rapacious privacy violator on the planet, is insisting...
https://jwz.org/b/ykUc
 5
20
1
repeated
5
20
1
repeated
 repeated
repeated
Ars Technica
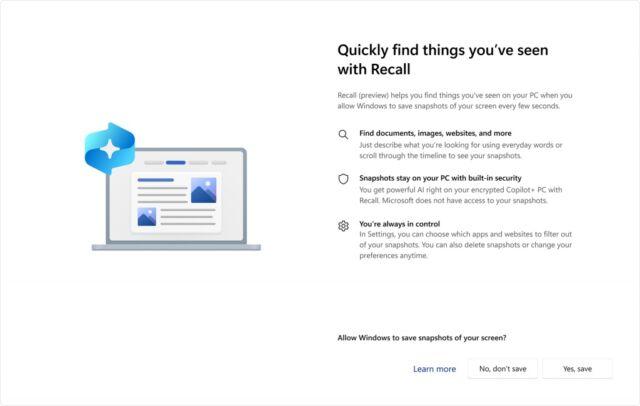
arstechnica@mastodon.socialMicrosoft makes Recall feature off-by-default after security and privacy backlash
Windows Hello authentication, additional encryption being added to protect data.
 2
5
1
repeated
2
5
1
repeated
yossarian (1.3.6.1.4.1.55738)
yossarian@infosec.exchangeperiodic reminder: you cannot "pass" a security audit. anybody selling you a passable security audit is selling you a lie, and anybody selling you a product that has "passed' an audit is lying to you.
a security audit can uncover bugs, or not uncover bugs, and can (in the words of the recipient) demonstrate positive or negative qualities about the codebase. but it cannot be "passed" or otherwise *endorse* the product or program itself.
2
3
1
repeated
kaoudis
kaoudis@infosec.exchangeI would equate writing your own parsers for fiddly formats that lack formal single specification and may even require implementers to know the right undocumented or verbally passed down lore with doing your own gas plumbing.
If you’re a pretty competent plumber and can turn the gas on and off you could try it right? Somebody has to do it and they usually get it right. And you’ve fixed a leaky sink tailpipe once or twice in your day.
But should *you* as a non gas plumber? My vote is no, your house could explode or you could die of noxious gas inhalation if you get it wrong.
I would equate using FFI to shoehorn such parsers from, say C++ into your nice “safe” main codebase language to then using an inappropriate connector type to attach a new gas range to your DIY job.
Should you do it? My vote is no, please let someone who is trained to do it. *Could* you do it? Nobody laid down a personal challenge, mate.
2
2
2
repeated
David Chisnall (*Now with 50% more sarcasm!*)
david_chisnall@infosec.exchangeThe worst thing about #recall is not that it's a security and privacy disaster, it’s that the root cause of the security problems is also the reason it will be completely useless.
Imagine that you are scrolling through some news aggregator or social media page and you spot something that’s interesting. You forget and then a few days later ask recall to find it for you. Recall has access only to screenshots and so will tell you ‘yes, that thing you found interesting, it was at http://mastodon.social’ and you will say ‘you are a total waste of battery life and I hate you’. It does not have access to the structure of the page, so it cannot extract the link to the specific post, it just does optical character recognition on the address bar. Most of the sites where it’s hard to find things do infinite scrolling, so knowing that ‘this thing was somewhere in this infinite-scrolling page’ is unhelpful.
If it had been designed as a solid piece of engineering, rather than a ‘please find a use case for this AI thing’ project, it would work more like Spotlight on macOS, exposing hooks for apps to provide structured data. Edge would extract the permalink fields and index them along with post content. If it had been designed like this, apps would be able to choose what to provide and so Edge could automatically skip any content of sites that you log into unless you opt in, and also opt out anything in a private browsing window. Office apps would be able to exclude files marked as sensitive (e.g. anything with PII or medical or financial data). The privacy implications would be much less bad, the performance would be better, and it would actually be useful.
This is fairly representative of a lot of the AI hype. By using machine learning, you can build something that could be done a lot better without AI. That’s not to say that there’s no use for ML models in such a system. Providing a feature extraction model for indexing would be useful, so I can search for ‘that paper I read that had a picture of an orange cat on the first page’ and it would be able to record ‘orange cat’ in the metadata for that picture when it indexed the PDF. It’s not the right foundation, because an existing off-the-shelf PDF parser can extract the table of contents and text with 100% accuracy, whereas ML-driven OCR on screenshots will fail if I’ve scrolled some of it off the window.
3
4
2
repeated
Prof. Sam Lawler
sundogplanets@mastodon.socialThe only feeling I have about starship is dread.
They want to use that to launch batches of HUNDREDS of Starlinks at once. And guess where all those Starlinks will end up? The pieces that don't make it to the ground will end up in our upper atmosphere, screwing up the stratosphere, the ozone layer, who knows what else because SpaceX isn't required to do any environmental assessments of this.
Shit. Maybe a good time to post this essay I wrote yet again: https://theconversation.com/an-astronomers-lament-satellite-megaconstellations-are-ruining-space-exploration-215653
3
29
0
repeated
abadidea
0xabad1dea@infosec.exchangeif you have a github integration that just started crashing, it's because the comment IDs have surpassed signed 32-bit range.
5
7
0
repeated
📣 Announcing the availability of:
- PHP 8.3.8
- PHP 8.2.20
- PHP 8.1.29
‼️ These SECURITY releases fix:
- Argument Injection in PHP-CGI
- Bypass in filter_var FILTER_VALIDATE_URL
- proc_open workaround Windows with escaping arguments for bat/cmd files
- openssl_private_decrypt vulnerability to the Marvin attack
Please upgrade ASAP.
Changelog: https://www.php.net/ChangeLog-8.php
Source: https://www.php.net/downloads
Windows: https://windows.php.net/download/
0
3
0
repeated
repeated
Nowhere Girl
gwynnion@mastodon.socialCompanies that bought a metric shit load of Nvidia processors want you to know how very badly you need a virtual assistant who spies on you and makes stuff up in order to justify it.
0
7
0
repeated
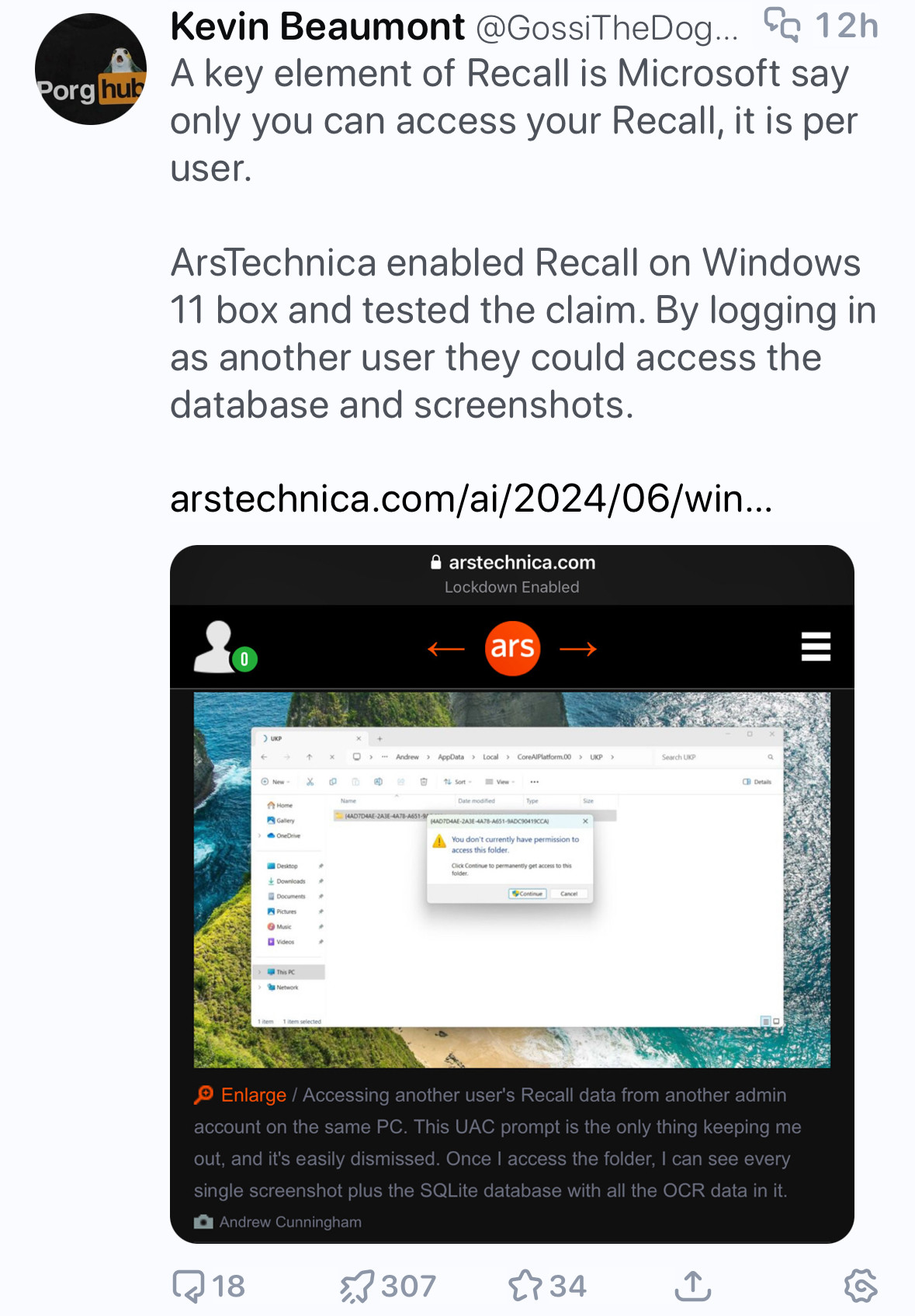
look i am not going to be a recall defender, nor am i a fan of the “uac is not a security boundary” bit, but this commentary seems… disingenuous. yes, your data is restricted to your user. yes, admins have full control over the machine meaning they can access your data. this shouldn’t be surprising. windows admin security boundaries are basically non-existent, i wish that wasn’t the case but that’s how it’s always been and will be for the foreseeable future
 3
1
1
repeated
3
1
1
repeated
Virus Bulletin
VirusBulletin@infosec.exchangeAhnLab researchers warn about phishing HTML files attached to emails that prompt users to directly paste (CTRL+V) and run commands. https://asec.ahnlab.com/en/66300/
 0
1
0
repeated
0
1
0
repeated
Alex Plaskett
alexjplaskett@bird.makeupOoh cool @travisgoodspeed has written a book on Microcontroller Exploits. Will certainly be adding this to my collection!
https://nostarch.com/microcontroller-exploits



 0
2
0
repeated
0
2
0
repeated
endrift 🏳️⚧️
endrift@treehouse.systemsAnyone have security contacts at Google? One of their IP addresses is spamming my ssh server, apparently as part of a botnet. Seems someone got compromised.
34.71.138.230 is the guilty party.
2
2
0
repeated
Michael Schneider
misc@infosec.exchangeI added disabling Recall to my HardeningKitty list:
https://github.com/0x6d69636b/windows_hardening
Disable Recall - User
[HKEY_CURRENT_USER\Software\Policies\Microsoft\Windows\WindowsAI]
"DisableAIDataAnalysis"=dword:00000001
Disable Recall - Machine (not yet official)
[HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Microsoft\Windows\WindowsAI]
"DisableAIDataAnalysis"=dword:00000001
1
2
0
repeated
Asahi Linux
AsahiLinux@treehouse.systemsIntroducing Honeykrisp: the world's first conformant Vulkan® 1.3 driver for Apple Silicon.
https://rosenzweig.io/blog/vk13-on-the-m1-in-1-month.html
 1
8
0
1
8
0