Posts
2530Following
647Followers
1459 repeated
repeated
hanno
hanno@mastodon.social
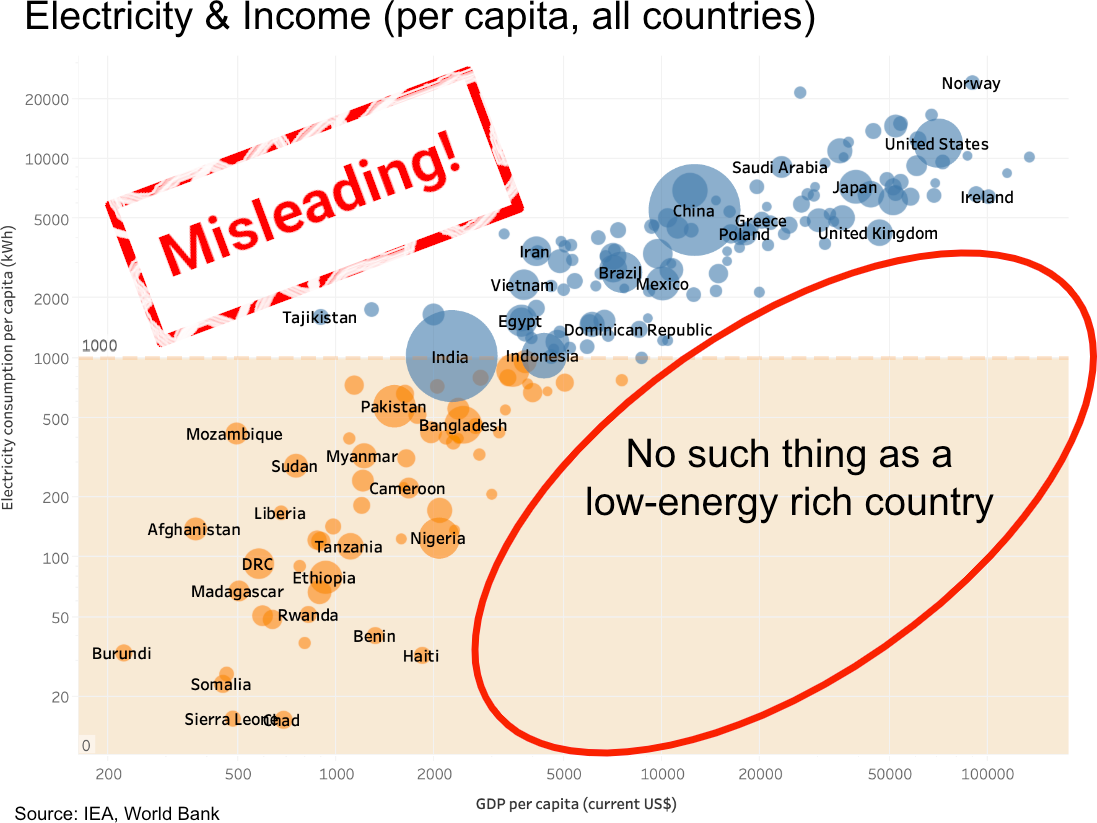
This widely shared infographic uses a trick to make its message appear much stronger than it actually is. It seems to show a strong correlation between energy consumption and the wealth of a country. By using a logarithmic scale, the correlation appears much stronger than it actually is. I covered this before in articles, and now have also uploaded a short video ⚡💸🎥 https://www.youtube.com/watch?v=2xZ6CihdKu0 🧵
 7
3
7
3
 0
repeated
0
repeated
Solarbird 
moira@mastodon.murkworks.net
@mcc (In short, as "AI summaries" corrupt more and more material, I think we're going to end up seeing more and more arguments where people are not reading the article, but instead are just the broken AI paraphrase, and starting fights based on what the LLM got wrong.)
1
2
0
buherator
buheratorhttps://www.smokescreen.io/deception-and-kerckhoffss-cryptographic-principle/
(Re: yesterdays fun little shitpost)
0
0
2
buherator
buheratorhttps://blog.convisoappsec.com/en/analysis-of-github-enterprise-vulnerabilities-cve-2024-0507-cve-2024-0200/
0
0
0
repeated
Cassandra Granade 🏳️⚧️
xgranade@wandering.shop@mcc This, this, this. Whether or not LLMs "work" (they don't), whether or not they can be ethically trained (they can't), whether or not they can be reduced to an energy and CPU scale that's reasonable to run locally (they can't), LLMs still fundamentally invert the relationship we have with written language.
1
3
0
repeated
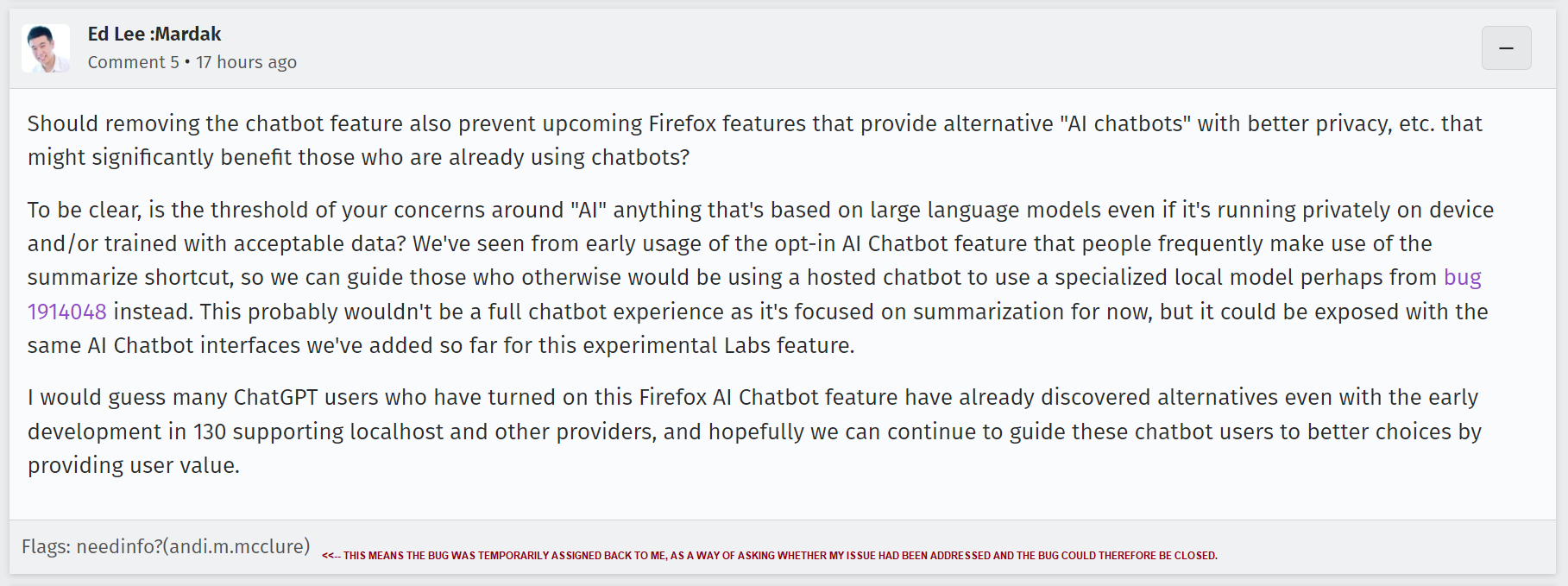
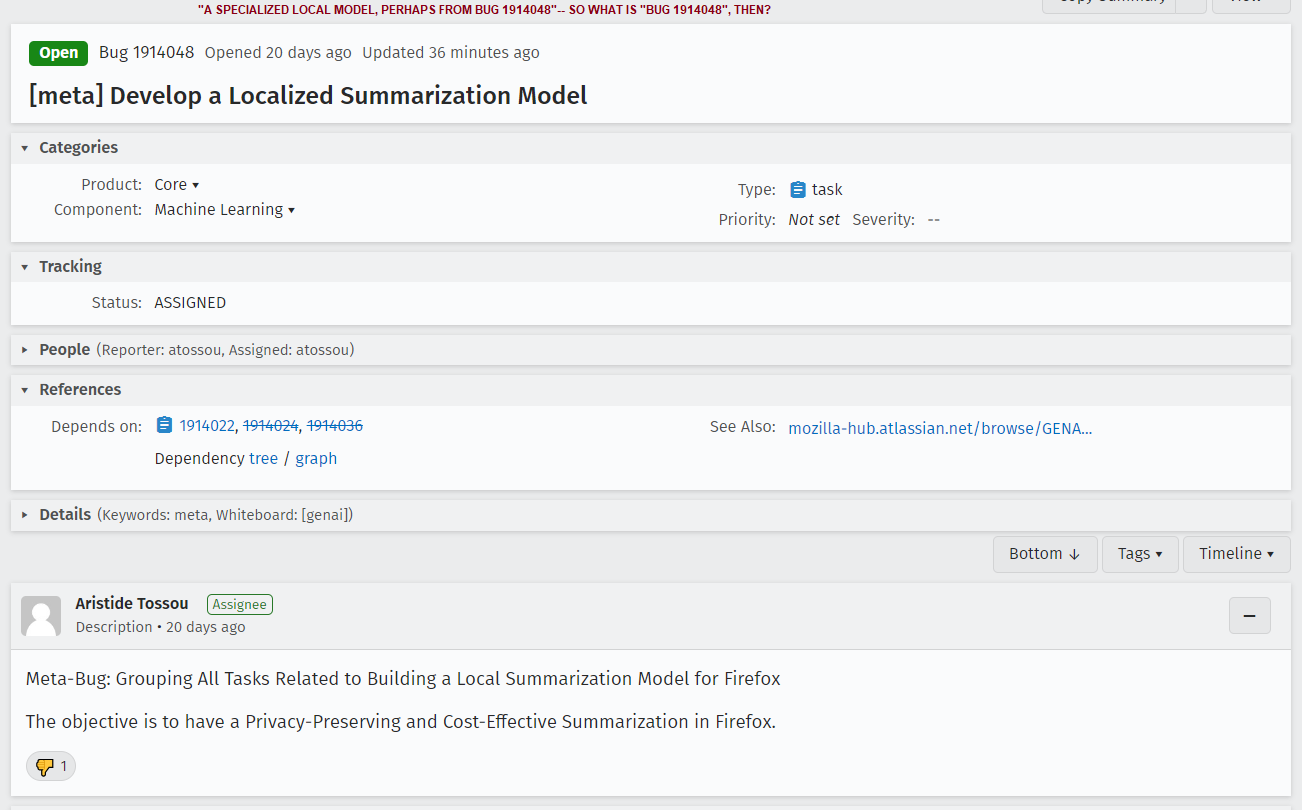
I have one contact from a Mozilla dev and a detail-free tracking issue to work from here. I can't know how this subject is being discussed within Mozilla and you should be clearly aware I'm speculating. But what I see here is, they view "summarization" as a component of the "AI chatbot" model which they can tear off and move into a local model, thus "solving" the privacy/safety problems.
Which alarms the heck out of me, as the other issues— licensing, environmental impact, and
➡️ lying ⬅️
remain.
2
2
0
repeated
Here is how I interpret what I see here. Mozilla, or the people within Mozilla driving the "AI chatbot" feature, view the "labs" chatbot feature as only step one of a larger plan. Their goal is to get people used to interacting with "AI" through the Mozilla sidebar, and once they're used to that, they want to encourage people to switch out OpenAI or Bing in this sidebar for Mozilla's AI (some part of which might be running locally).
In other words, Mozilla wants to be the next OpenAI.
 7
5
0
repeated
7
5
0
repeated
Binary Ninja
binaryninja@infosec.exchangeThere is a known issue in the latest stable 4.1.5902 we wanted to make folks aware of. If you save a bndb while debugging, the database can get into an improper state and it may appear to lose user changes. The issue is resolved in the latest dev builds.
For those who are using the latest stable, you can either switch to dev or avoid saving during debugging (saving after debugging is unaffected). Impacted users can contact support (https://binary.ninja/support/) or see: https://github.com/Vector35/debugger/issues/612
0
2
0
repeated
buherator
buherator
0
0
1
buherator
buherator
0
0
1
repeated
screaminggoat
screaminggoat@infosec.exchangewatchTowr: Veeam Backup & Response - RCE With Auth, But Mostly Without Auth (CVE-2024-40711)
Reference: CVE-2024-40711 (9.8 critical, disclosed 04 September 2024 by Veeam) Veeam Backup & Replication: A deserialization of untrusted data vulnerability with a malicious payload can allow an unauthenticated remote code execution (RCE). This vulnerability was reported by reported by Florian Hauser @frycos with CODE WHITE Gmbh @codewhitesec.
watchTowr doing what they do best, root cause analysis of vulnerabilities and breaking it down Barney style. Veeam Backup and Replication's CVE-2024-40711 has an authenticated RCE with a 9.8? watchTowr does patch-diffing (a lot of code and rambling). They name drop James Forshaw @tiraniddo in referencing “Stupid is as Stupid Does When It Comes to .NET Remoting”
Okay in reading through this, CVE-2024-40711 is actually comprised of two separate bugs. Veeam silently patched an improper authorization bug, then the deserialisation bug 3 months later. watchTowr claims that there is a way to bypass CVE-2024-40711 (details are still under embargo). They do not release a proof of concept due to the current situation and proclivity for ransomware actors to go after Veeam backups.
#cve_2024_40711 #vulnerability #rootcauseanalysis #cve #veeam #infosec #cybersecurity
0
3
0
repeated
Zig Weekly
zig_discussions@mastodon.socialData-Oriented Design Revisited: Type Safety in the Zig Compiler
https://www.youtube.com/watch?v=KOZcJwGdQok
Discussions: https://discu.eu/q/https://www.youtube.com/watch?v=KOZcJwGdQok
0
2
0
repeated
Cedric Halbronn
saidelike@infosec.exchange3 more weeks before my Windows Kernel Exploitation training at #HEXACON2024
Don't miss out! More info on contents -> https://www.hexacon.fr/trainer/halbronn/
0
2
0
repeated
Project Zero Bot
p0botPowerVR: DEVMEMXINT_RESERVATION::ppsPMR references PMRs but does not lock their physical addresses
https://project-zero.issues.chromium.org/issues/42451698
CVE-2024-34747
0
2
0
repeated
andersonc0d3
andersonc0d3@infosec.exchangeOkay, I figured out the answer. When entering the kernel via syscall, the architecture/instruction sets %ss from the %cs value + 8. When entering the kernel via interrupt, %ss is 0.
0
1
1
buherator
buheratorhttps://github.com/google/security-research/security/advisories/GHSA-3658-w6j3-w42r
0
1
2