Meredith Whittaker
Mer__edith@mastodon.world
📣THREAD: It’s surprising to me that so many people were surprised to learn that Signal runs partly on AWS (something we can do because we use encryption to make sure no one but you–not AWS, not Signal, not anyone–can access your comms).
It’s also concerning. 1/
 6
6
 31
31
 1
1
Meredith Whittaker
Mer__edith@mastodon.worldConcerning, bc it indicates that the extent of the concentration of power in the hands of a few hyperscalers is way less widely understood than I’d assumed. Which bodes poorly for our ability to craft reality-based strategies capable of contesting this concentration & solving the real problem. 2/
2
6
0
Meredith Whittaker
Mer__edith@mastodon.worldThe question isn’t "why does Signal use AWS?" It’s to look at the infrastructural requirements of any global, real-time, mass comms platform and ask how it is that we got to a place where there’s no realistic alternative to AWS and the other hyperscalers. 3/
3
10
0
Meredith Whittaker
Mer__edith@mastodon.worldRunning a low-latency platform for instant comms capable of carrying millions of concurrent audio/video calls requires a pre-built, planet-spanning network of compute, storage and edge presence that requires constant maintenance, significant electricity and persistent attention and monitoring. 4/
2
4
0
Meredith Whittaker
Mer__edith@mastodon.worldInstant messaging demands near-zero latency. Voice and video in particular require complex global signaling & regional relays to manage jitter and packet loss. These are things that AWS, Azure, and GCP provide at global scale that, practically speaking, others (in the western context) don’t. 5/
3
5
0
Meredith Whittaker
Mer__edith@mastodon.worldThis isn't ‘'renting a server.' It's leasing access to a whole sprawling, capital-intensive, technically-capable system that must be just as available in Cairo as in Capetown, just as functional in Bangkok as Berlin. Particularly given the high stakes use cases of many who rely on Signal. 6/
2
2
0
Meredith Whittaker
Mer__edith@mastodon.worldSuch infrastructure costs billions and billions of dollars to provision and maintain, and it’s highly depreciable. In the case of the hyperscalers, the staggering cost is cross-subsidized by other businesses–themselves also massive platforms with significant lockin. 7/
2
3
0
Meredith Whittaker
Mer__edith@mastodon.worldMeaning that infrastructure like AWS is not something that Signal, or almost anyone else, could afford to just “spin up.” Which is why nearly everyone that manages a real-time service–from Signal, to X, to Palantir, to Mastodon–rely at least in part on services provisioned by these companies. 8/
7
2
0
Meredith Whittaker
Mer__edith@mastodon.worldBut even if Signal had the billions needed to recreate AWS, it’s not just about money. The talent to run these systems is rare & concentrated. The expertise, the tooling, the playbooks, the very language of modern SRE came out of these hyperscalers, and is now synonymous with 'the cloud.' 9/
2
3
0
Meredith Whittaker
Mer__edith@mastodon.worldo, yes, Signal runs on AWS. It also runs on your phone, which runs on iOS (Apple) or Android (Google). And on Dekstop, via Windows (Microsoft). Each of these presents similar dependencies on large entrenched tech companies, and concomitant barriers and risks. 10/
3
3
0
Meredith Whittaker
Mer__edith@mastodon.worldIn short, the problem here is not that Signal ‘chose’ to run on AWS. The problem is the concentration of power in the infrastructure space that means there isn’t really another choice: the entire stack, practically speaking, is owned by 3-4 players. 11/
5
6
0
Meredith Whittaker
Mer__edith@mastodon.worldSo, Signal does what we can to provide a service w integrity in the concentrated ecosystem we're working in. We protect your comms w end-to-end encryption, so that we can use AWS and others as a highway across which to send Signal data in ways that don’t let AWS, or anyone else, gain access. 12/
2
4
0
Meredith Whittaker
Mer__edith@mastodon.worldTo conclude: my silver lining hope is that AWS going down can be a learning moment, in which the risks of concentrating the nervous system of our world in the hands of a few players become very clear. And that this can help us craft ways of undoing this concentration and creating real choice ❤️ 13/
19
7
0

Meredith Whittaker
Mer__edith@mastodon.world@yawnbox I don't think you have a clear understanding of what you're talking about, and it might be fun for you to look a bit more deeply into how TOR works and its dependencies.
1
1
0
Troed Sångberg
troed@swecyb.com@Mer__edith Agree - if you want to run your service centralized. Neither my Mastodon nor my Matrix-server need anything but my own self-hosting. Of course they won't handle billions of concurrent customers - but a few tens of thousands similar to mine will. Together.
I simply don't think Signal being centralized is a good thing. It's your choice, but alternatives do exist and those do not need hyperscalers.
2
1
0
Meredith Whittaker
Mer__edith@mastodon.world@troed I don't think you have a clear understanding of this space, but I hope you have a good time digging in and learning more.
2
1
0
David Penfold 
davep@infosec.exchange
@Mer__edith interesting engagement levels across different sites.
 1
1
0
1
1
0
@Mer__edith great explanation and thank you for that.
Is it possible to build a future promoting other competitors to AWS gathering partners (other executive leadership with different companies) who rely heavily on these services to help level the playing field as well as give applications like Signal multiple options to run their infra? It would be complex, but it already is anyway. I've learned over the years to be as redundant as possible in every aspect of your infrastructure which includes things like cloud providers.
I have ran redundant workloads in AWS, GCP, Azure and tried to tie that in with smaller orgs like Linode, OVH and have had success. I understand that Signal is far more complex and your service needs to be real time whereas in oil and gas(the industry I was in mainly during my career) not everything needed to be as real time as your application.
We need someone to kickstart us into balancing out the playing field to give other, smaller competitors a chance at the same time helping to make these applications more redundant in the event of a disaster like we just had. Costs for such a design would be high but overtime that could balance out as we get more competition flowing.
0
1
0
geofurb
geofurb@infosec.exchange@Mer__edith Is there any chance of Signal adding its own keyboard in the future? The input system seems like a pretty important privacy concern at the moment.
1
1
0
buherator
buherator
2
0
1
Dawid Wiktor
dawid@vebinet.com@Mer__edith It's possible to manage a real-time service without these companies, but it's challenging. I understand that it would hard for Signal to build and maintain its own infrastructure, but the questions is, if Signal team is considering what to do in the future to make impact of future outages (which may occur again) to have lesser impact on people who use it.
0
1
0
Troed Sångberg
troed@swecyb.com@Mer__edith Thanks for your condescending reply. I used to manage global SaaS within fintech with nodes in GCP, AWS and Azure and on multiple different continents.
3
1
0
Éric Freyssinet
ericfreyss@mastodon.social@Mer__edith Hello Meredith, all fair points of course, and I believe that many understood what happened. Isn't there a way to distribute the load in a fashion that it would not fail when US-EAST-1 at AWS is down ? (either with AWS itself or with other providers to balance the risks)
1
1
0
Talya (she/her) 🏳️⚧️✡️
Yuvalne@433.world@ericfreyss @Mer__edith
presumably that's on AWS to fix. the AWS deployment of Signal uses DynamoDB, which in theory is multi-region. however that service has a chokepoint in US-East-1 that is part of the AWS design and not something anyone other than them can fix - you can't choose to have the DNS for it be deployed somewhere else when you deploy to DynamoDB. it's AWS's task to make DynamoDB actually as multi-region as they advertise it being.
1
1
1
Simon Zerafa (Status: 
 😊)
😊)
simonzerafa@infosec.exchange
@Yuvalne @ericfreyss @Mer__edith
This was the comment I was hoping to find!
The issue seems to be how AWS itself is internally architcted for resilience, or in the case of the last outage contains points of failure.
This isn't surprising but it does present challenges. I doubt that AWS will fail the same way again but next time it will be some different unanticipated failure mode.
Hopefully AWS will now be looking at this and hopefully coming up with a solution 🙂🤷♂️
1
0
0
@troed @Mer__edith I might be missing your point but there does need to be A choice that doesn't require self-hosting; because I promise you my parents are not about to learn to run a Signal-like service for themselves, and I don't want to have to do it for them.
Otherwise services like WhatsApp exist, and they just work, so they'll just use that. Which means I have to use it too. The value of a messaging app is (IMO) ENTIRELY derived from who you know on it so it has to be easy to adopt.
1
0
0
Troed Sångberg
troed@swecyb.comThere's something inbetween "everyone selfhosts" and "everyone uses a single instance". Since you're posting on Mastodon, I do think you know what it is ;)
1
1
0
buherator
buherator
0
0
2
@troed yes but I'm posting from a "centralised" Mastodon instance (by which I mean it's outside of my control and there is a network effect beyond just me when this instance experiences issues).
I'm on Mastodon because the people I'm interested in following are here. But I have less than zero interest in self-hosting my own server.
This is only a partial solution IMO, and only works as well as it does because Mastodon is not required to be "real time" like a voice call.
1
0
0
Troed Sångberg
troed@swecyb.com@_calmdowndear So, your parents don't need to self-host yet they can be on a network that doesn't require everyone to be on the _same_ centralized instance.
My other example was Matrix. It's like Signal, but decentralized like Mastodon. It fully supports voice and video calls.
1
1
0
fiery
fiery@snac.bsd.cafe
1
0
0
@troed so "Mastodon is down" is a thing that could still happen if the right piece of infrastructure dies. Because that's what happens from the user perspective - yes, the network may be up but if "your" instance is dead and you can't interact with it, then who cares?
I can't comment on Matrix too much as I hardly ever use it (unless required by some software using it for support). But what I have seen of it is a very frustrating user experience.
1
0
0
Troed Sångberg
troed@swecyb.com@_calmdowndear Absolutely - just like your local ISP can go down and those affected say "the Internet is down".
The rest of the world still works fine though.
0
1
0
datum (n=1)
datum@zeroes.canearly everyone that manages a real-time service–from Signal, to X, to Palantir, to Mastodon–rely at least in part on services provisioned by these companies
Mastodon doesn't, though?
There certainly will be servers hosted on AWS but when AWS went down, most Mastodon instances stayed up, and people were cracking jokes at more centralized platforms.
2
0
0
Meredith Whittaker
Mer__edith@mastodon.world@datum Mastodon is distributed at the level of the protocol, not infrastructure. Sure, some people use a server in their closet, but most license hyperscaler infra to host their mastodon instance.
Meta note, we seem to be dealing with a confusion in what the term "distributed" means in this context.
0
0
0
Dan Stowell
danstowell@mastodon.social@Mer__edith Thanks, your explanation is helpful. Does it suggest that text-messaging should perhaps be the focus? I'm amazed that video/audio is possible, but it incurs much more massive requirements - it seems that the video/audio service is constraining the possible infra choices for the text-message service.
1
0
0
Meredith Whittaker
Mer__edith@mastodon.world@danstowell No, because no modern and useful comms platform provides only text messaging. And if your platform doesn't provide normative features and functionality, people won't use it. And if they don't use it--even if you do--you can't use it either. The network effect rules communications effectiveness.
0
0
0
System Adminihater
systemadminihater@cyberplace.social@Mer__edith The reason AWS is affordable is because they are *still* subsidizing your invoices by 80%. When doing price comparisons assume that one day AWS will start charging 5x more once they have succeeded in killing the rest of the competition. All of them will. Im certain if AWS was charging what it costs to run that service that colo or any other option would be just as viable from a price perspective. They absolutely cannot compete on anything other than price. They are really bad at it
1
1
0
Talya (she/her) 🏳️⚧️✡️
Yuvalne@433.world@buherator not only does Signal already do that as @Mer__edith mentioned, but routing to GCP is exactly what Signal did during the latest outage, hence why for many users it recovered before AWS did.
2
0
3
Alessandro Corazza 🇨🇦
alessandro@mstdn.caIt's easy to gloat about AWS but if Hetzner goes down it takes half the Fediverse with it. Same problem, different vendor.
1
1
0
daughter of lilith 
marta@corteximplant.net
The whole thread is about how AWS and other big scale providers created the international infrastructure that is needed for Signal to run smoothly and that infrastructure would be impossible for Signal to set up independently. But Mastodon (and Matrix) is decentralised, so yes, if there was one big Mastodon server it would need these resources, but isn't it one perk of decentralisation that because there are so many independent people doing it, creating that international infrastructure becomes possible?
I've been using Signal for almost 10 years and Mastodon/fediverse for around 3 including hosting my own instances (both self-hosting and using small-medium scale server providers) and they have been very comparable in speed and reliability.
1
0
0
Meredith Whittaker
Mer__edith@mastodon.world@marta Decentralization at the level of protocol--in Mastodon's case via ActivityPub--does not mean decentralization at the level of infrastructural dependence.
0
0
0
Julian
j_r@social.jugendhacker.de@Mer__edith maybe Signal should reevaluate its standpoint against federation then? This would enable different entities to run different parts of the network in different regions and will remove the need for a globe spanning compute platform...
0
0
0
@Mer__edith @troed This is a really shitty reply, especially when multiple experienced people are expressing the same opinion.
1
0
0
Meredith Whittaker
Mer__edith@mastodon.world@JadedBlueEyes @troed I'm sorry if it landed harsh.
First, I don't think not knowing things is inherently bad or shameful--it's where learning starts, etc. Second, there's a misunderstanding here, whoever is expressing it: decentralization at the level of a protocol--ActivityPub or w/e else--is NOT the same thing as decentralization of infra. People running mastodon instances, or Matrix servers, or other fedi systems, are also in most cases leasing infrastructure from hyperscalers to do so.
2
0
0
Troed Sångberg
troed@swecyb.comYou're claiming something that isn't true (no, most people are not using hyperscalers - and yes - I know many people who run Matrix-instances) - and then respond to people that we don't have a clear understanding of this space.
It didn't "land harsh", btw. It just completely changed my impression of you since you actually seem to believe it.
0
1
0
Talya (she/her) 🏳️⚧️✡️
Yuvalne@433.world@Mer__edith @buherator thank you. I'm just a Signal nerd who spent like half of the outage being on the forum and I'm in essence just repeating stuff said there 
0
0
0
yawnbox
yawnbox@disobey.netWith respect Meredith, i’m talking about decentralized protocols and their capability to not depend so heavily on the service providers you’re arguing for. Tor Project has shown how possible it is (i used to work there, and it’s spelled Tor not TOR).
I listened to Moxie’s aversions to decentralization for years. That’s what I keep seeing now, with posts like these. I also understand the value of huge cloud providers, I’ve worked for many companies who use them, and have worked for them, and I understand why you depend on them and how important that is to a high quality service. Thank you for all that you all do.
But what conversations does Signal Foundation actually have on the topics of resiliency through decentralization? How much money could you save by allowing the community to take on aspects of the network? How much resiliency and trust could be gained, without losing performance?
6
3
0
buherator
buherator
1
0
3
Troed Sångberg
troed@swecyb.comHetzner isn't a hyperscaler though. Meredith seems to confuse people choosing a VPS instead of hosting at home with using advanced AWS (et.al) services for scaling.
There seems to be a real disconnect in understanding here.
1
1
0
Talya (she/her) 🏳️⚧️✡️
Yuvalne@433.world@buherator @Mer__edith i know users in different regions got service at different times. i remember someone mentioning on the forum that Singapore was one of the hardest hits, taking many hours to come back online. and of course there were the users who weren't affected at all, which to my understanding were mostly in North America.
i got service back in Central Europe relatively early on, when AWS was still coming back online.
1
0
1
Alessandro Corazza 🇨🇦
alessandro@mstdn.caWhat's the difference if everybody uses the same few VPS providers? The technical details of a massive outage don't really matter - the problem is that we have very large single points of failure, but the immense technical demands of modern tools mean that there are few alternatives.
1
1
0
Talya (she/her) 🏳️⚧️✡️
Yuvalne@433.world@buherator
this is the thread i'm taking my info from.
https://community.signalusers.org/t/signal-service-outage-2025-10-20/72317?u=rassilon1963
1
0
1
Troed Sångberg
troed@swecyb.comIf you use AWS (et.al) services it's difficult to move your SaaS to another provider. If you're using a VPS it's trivial.
(And we aren't all using Hetzner, or OVH, etc)
0
1
0
David Penfold
davep@infosec.exchange
@yawnbox @Mer__edith Tor is basically a glorified network protocol (albeit very smart) so having it distributed by design is less of an issue.
I agree that making Signal more robust through decentralisation would be great, but this sort of thing gets more difficult the higher up the stack you go, especially when it wasn't part of the core design principles.
1
1
0
Michael Stanclift
vmstan@vmst.io@davep @Mer__edith like count here also may not be accurate unless you view it from mastodon.world
0
1
0
fellmoon 🏴
fellmoon@bsd.network@yawnbox @Mer__edith I think moxie made a pretty clear point on his view of decentralized vs centralized with his ccc-talk a few years ago.
That aside, Tor may be able to provide in terms of uptime, but latency? If I'd be in signals boots I would not build on a network run by people on all kinds of hosting with no sufficient ability to have some kind of guarantee on the QoS aspect.
0
0
0
ECHAEA
Teratogenese@mamot.fr@Mer__edith
I remember SETI distributed a program that could, if installed on PC's, help them to run calculations to detect alien intelligence signs from radiotelescope observation files.
I wonder why there wouldn't be an option on signal desktop to allow PC's to be able to carry part of the traffic as a node (like Session messenger does).
This could help alleviate the effects of the next AWS outage, wouldn't it?
0
0
0
Jan Wildeboer 😷
jwildeboer@social.wildeboer.net
@Mer__edith What was surprising to me was that a problem in one AWS availability zone caused a persistent outage for my Signal connection that lasted at least 3 hours. I expected there would be some sort of automated failover to another zone or cloud provider happening in the background, limiting the downtime to, say, maximum 15 minutes. I hope your internal post-mortem is taking a look at how to be better prepared next time.
1
0
0
Jan Wildeboer 😷
jwildeboer@social.wildeboer.net
@Mer__edith (For me this unexpected outage was quite dramatic, as it happened at exactly the time my son was going into surgery and we communicate a lot via Signal, so my "best wishes!" didn't go through and his "All went well" arrived with a significant delay. Murphy, I know. Things go wrong when you least expect it. He is fine and all is good :)
0
0
0
Jan Wildeboer 😷
jwildeboer@social.wildeboer.net
@toxy And that's what SRE (Site Reliability Engineering) should solve — to have a (temporary, even manual for these very rare cases) failover solution to, if needed, a completely different provider, in case that one provider goes down. That is my hope. That even if this rare case never happens again, there should be a plan available. @Mer__edith
1
0
0
Tom Bortels
tbortels@infosec.exchange@Mer__edith @systemadminihater
There are two issues with that disaster scenario.
First - AWS has numerous healthy competitors including google's GCP and Microsoft's Azure and Oracle's OCI, and they are gaining rather than losing market share. Their immanent demise is (sadly) unlikely. So robust competition seems pretty assured. And even if those three disappeared, there are other wildly strong competitors (Cloudflare!) waiting in the wings.
Second - self hosting never went away, and at a certain scale it's not just viable but still beats AWS in many ways. Point being - a 5x price increase would mean a sudden mass exodus from AWS. But that's unlikely as well - AWS pricing is both consistent and downward trending, with certain weird exceptions.
The reality is there is no magical superior never-failing alternative to AWS. Shit happens. You do not succeed by never failing - you succeed by reducing the impact of the fails. Hosting on high-resiliency proven platforms like AWS is part of that strategy.
If Signal usage is a single-point-of-failure issue for someone - that's their problem, not Signal's.
0
1
0
Daniel Gultsch
daniel@gultsch.social@Mer__edith What if, instead of running a global comms platform for millions of people that requires AWS level infrastructure, we run a bunch of small, local ones that all federate and interop with each other? 😍
1
0
0
prom™️
promovicz@chaos.social@Mer__edith Maybe we should focus more on cloud interop, to reduce migration costs and enable better market dynamics? Too bad, EU is mostly just wasting money with their sovereignty initiatives…
2
0
0
punIssuer
punissuer@universeodon.com@promovicz what would you suggest the EU should do differently? They cannot force US companies to do anything unless it affects EU citizens, and Amazon's services aren't targeted at consumers. On the other hand, the DMCA makes reverse engineering a felony
1
0
0
prom™️
promovicz@chaos.socialStates have no obligation to be fair with monopolies.
* regulate their prices (consumer or otherwise)
* withdraw their advantages (tax, market, regulatory)
* use cartel law
* use state money against monopolies
maybe:
* reintroduce our DMCA waivers
(Germany had a law for it)
0
1
0
Max Lee
the_moep@mastodon.de@davep @yawnbox @Mer__edith Pretty sure that wouldn't even be as big of an issue as long as you don't try to exit the network.
You could even potentially improve the throughput ability by making every client that wants to use the network a node that relays traffic when it doesn't have active calls, however that's not suited to be automatically activated on mobile devices with limited power or even data caps. (But I would imagine people would be willingly donate resources to such a network if a simple separate application was offered the same way as it's done with TOR already)
0
1
0
Jan Wildeboer 😷
jwildeboer@social.wildeboer.net
@toxy My fear is that many organisations will shrug this off as "too rare to prepare for" event :( I hope Signal can help here by sharing a possible solution (should they find one, of course) @Mer__edith
0
0
0
Bernd Paysan R.I.P Natenom 🕯️
forthy42@mastodon.net2o.de@jwildeboer @toxy @Mer__edith You need to run the failover solution all the time, because if it isn't life tested, it will very likely not work.
So you better design for at least a federated system. That's a much better design decision, anyways.
0
0
0
Cassandrich
dalias@hachyderm.io@yawnbox @Mer__edith Not once the number of active users approach even a fraction of number of active Signal users, without vastly expanding number of exit nodes etc. That could happen but it requires large scale benevolent effort and resource expenditure.
0
0
0
Tilman
gilbus@metalhead.club@troed @Mer__edith Than you, obviously, should have no problem setting up an alternative with the same features and sizing as signal 👍
1
0
0
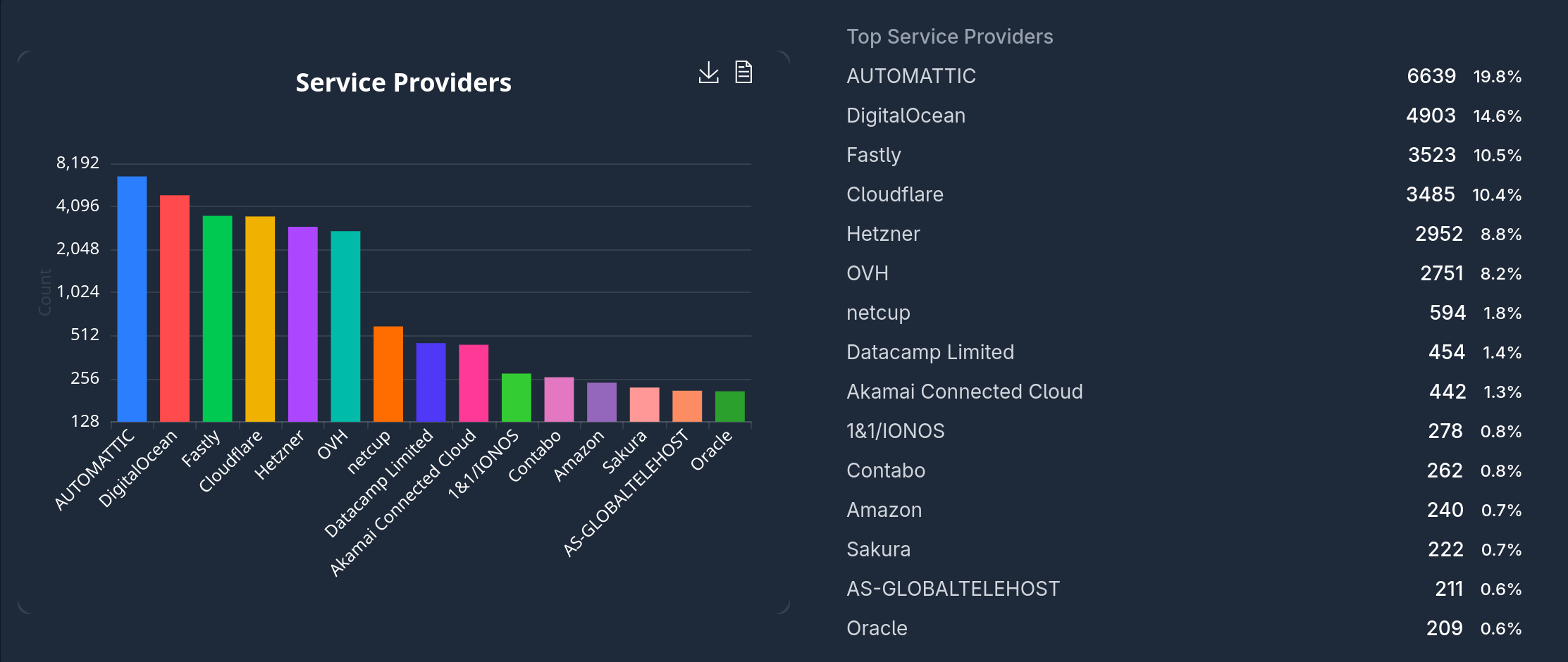
Jonathan Cremin
jonathan@social.crem.in@Mer__edith @JadedBlueEyes @troed in reality the hyperscalers barely register. See https://fedidb.com/stats and https://blog.benjojo.co.uk/post/who-hosts-the-fediverse-instances for more details. Hosted from people's homes likely outnumbers all of the hyperscalers combined.
 1
1
0
1
1
0
garry
repeattofade@tootr.co@jonathan @Mer__edith @JadedBlueEyes @troed that doesn’t change the fundamental point though; you can run a mastodon server on a raspberry pi but you cannot run something like signal without using at least 1 of about 3 or 4 american tech companies
1
0
0
Troed Sångberg
troed@swecyb.comI don't know if we're having the same discussion. No, you cannot run a centralized service like Signal without doing so - but since no one is claiming that either I'm not sure what your point is.
You can however run something like Signal that's decentralized. We know this, since it exists. It's called Matrix, and many people in the Fediverse also run Matrix instances.
1
1
0
Kristin (vis.social Admin)
kristinHenry@vis.social@Mer__edith not so surprising, as it's very difficult to do anything at any scale online and avoid AWS entirely.
The surprise shouldn't be about Signal, it should be a rallying cry to build diverse infrastructure.
0
2
0
M Berberich
m_berberich@chaos.socialMastodon? The comparison is flawed.
You can run Mastodon without AWS, etc. just fine.
You even can run an instance in your basement if you want.
0
0
0
garry
repeattofade@tootr.co@troed @jonathan @Mer__edith @JadedBlueEyes I feel we all understand the landscape, what exists and why
this just feels like a really unproductive, unhelpful thread from foss decentralised self-hosting absolutionists, trying to say they understand how to run signal better than its president
use matrix, by all means; try getting your family and friends to use it too. good luck. “perfect” really can be the enemy of good (or in this case, privacy).
2
0
0
Troed Sångberg
troed@swecyb.comSo far it seems Meredith does not know how decentralized service like the Fediverse and Matrix work (the claims that most use hyperscalers). No one is however claiming that we know how to run _the centralized service Signal_ better. We're saying maybe don't be centralized.
"try getting your family and friends to use [Matrix] too. good luck."
Thanks, yeah, the whole family does - including my elderly parents. It seems you might not know the subject you're having opinions on?
0
1
0
Third spruce tree on the left
tezoatlipoca@mas.to@daniel @Mer__edith Even _IF_ it were possible to create a black box version of "distributed Signal mesh node in a box" that you could run in your basement to help make Signal more tolerant - I mean with enough $ and willpower Im sure it could be done - there's still the question of: if you don't control physical access to the node, there's still potential for attack regardless of how much encryption and protection. Would you ever be able to trust it completely?
1
0
0
Julian
j_r@social.jugendhacker.de@tezoatlipoca @daniel @Mer__edith with global hyperscalers like AWS you don't exactly control who has physical access to your node either. You simply trust in Amazon holding up to their promises 🤷
0
0
0
ArneBab
ArneBab@rollenspiel.social@Mer__edith At least for messaging I found that 30s latency are acceptable to most. People no longer expect their tools to be fast, and they type slowly.
That does not solve video and audio; WebRTC may help.
One step forward could be to change education so that more than a few handful people understand how peer to peer networks of the past managed to connect millions of people with a handful of servers and ISDN bandwidth.
My humble contribution:
https://www.draketo.de/software/p2p-talk.pdf
https://www.draketo.de/software/p2p-talk
 1
0
0
1
0
0
ArneBab
ArneBab@rollenspiel.social@Mer__edith ⇒ push functionality out of the cloud bit by bit, as people re-learn what works and what fails.
Experience with that is scarce, though. Interest seems quite big, but polluted by crypto-coin agenda.
Anyway: thank you for your writeup!
0
0
0
ArneBab
ArneBab@rollenspiel.social@lexinova do they actually expect that?
Don’t they have at least 200ms of transitions and animations before they even see the message?
I’ve been communicating with IRC over Hyphanet for a while now that has 30s round-trip-time, and it’s strangely barely noticeable.
The main issue may be the notification "server received your message" (✅ ✅) and the info "other side is typing".
0
0
0
ArneBab
ArneBab@rollenspiel.social@lexinova Hosting infrastructure for multimedia communication of 100 million users¹ with just 50 employees¹ actually is hard.
¹ https://backlinko.com/signal-stats
So I do not think your points apply.
0
0
0
Tilman
gilbus@metalhead.club@promovicz @Mer__edith You mean something like https://sovereigncloudstack.org/ ?
The intial phase was also financed by the EU and German government ;)
0
1
0
DrYak
dryak@mstdn.science@ArneBab @davep @yawnbox Note that in the specific use case of Signal: given their threat model, "direct peer-to-peer connections by default" are not desirable. You'll need to bounce the audio&video traffic by default to make it more costly to infere who is talking with whom.
So the fact that working NAT and IPv6 help rely less on TURN servers won't help decentralize that much.
1
0
0
ArneBab
ArneBab@rollenspiel.social@dryak Maybe a start could be to switch to direct peer-to-peer connection if Signal sees that both sides are in the same subnet (i.e. on the same wifi).
In that case they connect to the signal server for connection with a voice-data profile *at the same time* which already gives away that they are talking, so staying in the subnet with a direct peer-to-peer connection would reduce the total privacy loss.
1
0
0
ArneBab
ArneBab@rollenspiel.social@dryak but firstoff, to stop discussing with too little information: the reason they use a forwarding server is that a single device can’t send video to 40 people via direct connections.
Here’s their description: https://signal.org/blog/how-to-build-encrypted-group-calls/
That also shows the level of complexity involved already.
1
1
0
Ben Aveling
BenAveling@infosec.exchange@Mer__edith does that mean that it could be made possible to fallback to a system where messages still get through, just not in real time?
0
1
0
Paul_IPv6
paul_ipv6@infosec.exchangei'm more concerned that signal do best practices in terms of redundancy/failover and data encryption for cloud. it's quite possible to do cloud (or multi-cloud) robustly but it takes extra effort/engineering/expense over more minimal uses of a cloud service.
can you give any details of your multi regional, multi-cloud use, active/fast failover, etc.?
0
1
0
Paul_IPv6
paul_ipv6@infosec.exchangei love this goal but you've done a great job of laying out why it's really hard, really expensive, and daunting enough that even the EU is struggling with it.
protocol changes can help but at a certain point, you hit speed of light and i don't think we're quite at the stage of engineering around that yet. :D
thanks for this thread. good to discuss these things, not just lay blame on a provider failure.
0
1
0
fiery
fiery@snac.bsd.cafe
1
0
0
casey is remote
realcaseyrollins@noauthority.social
2
0
0
fiery
fiery@snac.bsd.cafe
0
0
0
But I absolutely get why something like Signal would use a cloud provider. Could it be done entirely on-prem? Quite probably. However could they do it within a business model that would allow the scale of users to use it as they have today without charging significant fees to use it? I highly doubt it. This would hold true for anyone wanting to build a service like theirs that would operate on the their scale. The bandwidth and other infrastructure would be immense and super expensive to buy and maintain. The only folks able to provide that would be big telco, tech companies.
Could it be all decentralized ala the Fediverse? Sure and such services exist. But, much like the Fediverse, getting user adoption would be much more difficult and tour audience would be those tech savvy enough to use what’s already out there. I mean, for example, Matrix/Element exists. Quite secure, very decentralized. But it’s not for the general public.
1
0
0
fiery
fiery@snac.bsd.cafe
1
0
0
varx/social
varx@cybersecurity.theater@Mer__edith To clarify, are you multi-region within AWS? A bit hard to find info on this.
(A little concerning that so many people are worried about the privacy implications of Signal running on AWS... maybe some missing education on E2EE.)
0
0
0
Andreas Fink
afink@mastodon.sl@Mer__edith but its also concerning that a failure somewhere in the US brings down Signal users in Switzerland, Turkey , Iceland, Sierra Leone and Nigeria. Yes hyperscalers are nice as they are everywhere but the dependency becomes brutal and expensive. Im running myself a backbone across multiple continents and redundancy is an absolute must. Signal has failed here. Blaming only AWS is the wrong path. Signal is big enough to do it better. Thats why I am a long term subscriber of it.
0
0
0
synlogic4242
synlogic4242@vivaldi.net@Mer__edith I'm sure millions of folks appreciate your service and the work you all do. but I think that 2025 Oct 20 outage revealed Signal has a de facto SPOF on AWS us-east-1. its an architectural flaw not unique to Signal, obvs, since it bit lots of other systems around the world. I do hope your team can devise a way to change your architecture to remove that SPOF
0
0
0
boredsquirrel
Rhababerbarbar@tux.socialUse a privacy respecting keyboard then. But fair point for sure, especially for newbies
0
0
0
Dimitris Nakos, MSc
nakdim@mathstodon.xyz@Mer__edith The even worst part imo is that usually when a smaller player comes into play and they have LOTS of brains and rare talent and passion and love for what their doing, will either get lost because people's everyday life is soooo dependent on these evil corps. OR these corps. will buy them out... BUT that means that more effort needs to be put in decentralization, as way of life of sorts. As a stand. Of stop using one thing for everything and instead try to have more things that do ONE thing and do it well. Decentralization = more control from the person and less control from the big players. Centralization is the exact opposite... But it's easy... :/
0
0
0
Mike Fraser
mike@thecanadian.social@Mer__edith I understand what you're saying but I also wonder if maybe you've been sold a bill of goods. I run a real time communications company (admittedly very much smaller) and one of our core philosophies has always been data sovereignty. Of course as you rightly noted we can't build data centers but there's plenty of space for lease globally where you can scale you're own gear. We've made access to the physical layer a priority, maybe Signal can as well?
0
0
0
varx/social
varx@cybersecurity.theater@lexinova Not necessarily. I recall something about AWS *itself* having some things still centralized in us-east-1. And Signal might rely on other vendors that aren't multi-region. You get the idea.
I'm honestly fine with some downtime here and there. I think people should be more chill about it in general.
1
0
0
varx/social
varx@cybersecurity.theater@lexinova Realistically, they have to make tradeoffs about how they spend their time and energy.
They're not saying it here (and it would be nice if they did!) but they could choose between multi-cloud resilience or doing product development. I think most people would prefer the latter.
0
0
0
Talya (she/her) 🏳️⚧️✡️
Yuvalne@433.world@simonzerafa @ericfreyss @Mer__edith
i do want to mention something important, which is that Signal doesn't only use AWS, and actually the fact they don't was key to them recovering faster than AWS did by rerouting users. however when the issue on AWS is as fundamental as the DNS for DynamoDB being broken, there's gonna be downtime for some users, there's not really a way to go around that.
0
0
1
william.maggos
wjmaggos@liberal.citylooking at your replies to replies here that seem to make sense to me (especially re decentralization), you're telling them they don't know what they are talking about. well I definitely don't.
like with debates re #ATproto and #ActivityPub, I have thoughts but I know that we really need to see the experts debate each other more somehow. I don't think it happens enough. so I'd say the same re #signal and #matrix etc.
1
0
0
xyhhx 🔻
xyhhx@nso.group@wjmaggos meredith gets a lot of replies that could be answered with a little bit of research or could be answered by anybody, which may explain the short replies; but i can try to answer you
1
0
0
xyhhx 🔻
xyhhx@nso.group@wjmaggos what meredith is explaining is the scope of the infrastructure that signal absolutely needs in order to provide the service it does at the quality it requires, and that there are extremely few options that satisfy those needs
to say building their own infra would be prohibitively expensive wouldn't begin to describe it
1
0
0
xyhhx 🔻
xyhhx@nso.group@wjmaggos signals threat model and security guarantees can't be met with decentralization like matrix, fedi, or atproto, either. when disparate servers communicate, they have to know how to relay messages between each other, which leads to a lot of metadata leakage (as is the case with matrix)
tor likewise has mitigations for time based correlation attacks, which are great for its use case; but would cripple signals quality
2
0
0
xyhhx 🔻
xyhhx@nso.group@wjmaggos i agree that it sucks to rely on amazon (or google or microsoft), but its the reality of internet infrastructure right now
it's relatively true that there are some attacks one could leverage in this scenario (particularly "harvest now decrypt later" attacks), but signal was very quick to adopt post-quantum cryptography which should provide a pretty good confidence that those attacks aren't feasible for the foreseeable future
0
0
0
zaire arcana
soop@outerheaven.club@xyhhx @wjmaggos @Mer__edith ewwwww signal shill ewww hey fedi cancel this user
1
0
0
@soop @wjmaggos @Mer__edith @xyhhx just say you don't have friends and keep it pushing dog
0
0
1
Jonathan Cremin
jonathan@social.crem.in@repeattofade @troed @Mer__edith @JadedBlueEyes those are great arguments, but the one Meredith is taking on this thread is "look, Mastodon can't/doesn't do distributed infra" when the data says that actually yes it does.
I actually don't have a strong view on the centralisation of Signal, but seeing Meredith talk down to people (see replies on this and other threads) and then be wrong on the facts is pretty galling.
0
0
0
Zach 🇺🇸 🇮🇱
mrRobot@infosec.exchange@jack @Mer__edith I’ve actually been using #SimpleX recently myself in addition to #signal for conversations where I want the strongest privacy posture. It’s doing a lot right: strong FS properties, reduced metadata exposure, and no central identity system. So I’m not arguing from inside Apple’s walled garden here.
Though I still get uneasy when #privacy gets reduced to a binary grid of checkboxes. Private enough always depends on who the adversary is, what they want, and what the people you’re talking to will actually use. Cryptography isn’t the only variable in the real world.
On #Apple/iMessage: the original client-side photo-hash plan was a real problem, though that rollout was scrapped. The current “communication safety” feature for minors doesn’t break adult E2EE. It might evolve into something dangerous later, but at the moment calling it disqualifying feels more like a principled fear of direction than a present-day compromise.
#Threema’s history with limited PFS and audit transparency is worth criticizing. Though if they’ve now implemented PFS across the board, I’d prefer to see more independent scrutiny before writing them off as perpetually “not private enough.” Once again, context matters.
SimpleX gives stronger guarantees for high-value targets, sure. Yet adoption friction introduces its own kind of risk. If I push everyone I know into tools they won’t stick with, they’ll drift right back to far worse defaults. Usability failures can erase all the theoretical privacy wins.
So my stance looks something like this:
• Use the strongest tool that your social graph will realistically sustain
• Treat all vendors as temporary allies, not saviors
• Demand transparency and scrutiny from whoever holds the keys
• Always ask “private enough for whom?”
Security is a negotiation with reality, not a purity contest. You and I may have similar goals and even use the same tool for sensitive chats. We just assign slightly different weight to the tradeoffs.
Happy to keep comparing notes as these apps evolve. Yesterday’s “maximum” becomes tomorrow’s minimum pretty quickly.
0
0
0
mapto
mapto@masto.bg@troed @Mer__edith hopefully the pros and cons in this comparison could provide useful context:
https://hapyyr.com/@bogo/115401249466782443
But ultimately this is not a conversation about features. It is about priorities. And as already said on this thread, decentralization is not compatible with low latency.
1
0
0
Troed Sångberg
troed@swecyb.comI've indeed seen several people claim that low latency requires centralization, but I don't think I've seen anyone show why that would be true.
My (way back when) background is in telecom and that has always been low latency and decentralized.
1
1
0
Jan Vlug
janvlug@mastodon.socialI've been using #Signal from the very beginning (TextSecure times), and I've been advocating Signal a lot.
But the centralized architecture, instead of a federated decentralized approach is something I never liked. Also the focus on BigTech platforms (IOS, Android) is something I do not like. I'm using a #Librem5 #Linux phone, but there is no official primary client for Linux.
Still, I'm donating, but I would appreciate addressing centralism and #BigTech dependency.
2
0
0
David Chisnall (*Now with 50% more sarcasm!*)
david_chisnall@infosec.exchangeI don’t believe federation is possible without leaking a huge amount of metadata, but I believe decentralisation is. It would be great to see Signal actively investigating the options in the design space that enable it.
The client side is a bigger problem. The choice of license has two major impacts:
- Only Signal (who have a CLA and so are not bound by the license) can publish anything on the Apple App stores. This means that a legal injunction against Signal shipping the app in a country will cut off around half of the users in that country.
- No one can integrate Signal with their back end systems. A load of people install WhatsApp or WeChat because some institution uses them to communicate with customers and then uses them to talk to friends because they’re already installed. I’d love for my bank to be able to communicate with me via Signal instead of POTS, for example, and then for Signal to benefit from the network effects: if the bank says ‘install Signal to communicate with us securely’ then that’s a few million folks who will have Signal installed already.
It is very rare for a protocol to become ubiquitous without a permissively licensed reference implementation.
0
1
0
Therefore, if you actually want users, you're going to have some amount of centralization. That means you need to run on something, either your own gear or someone else's. And at the scale that Signal wants to run, cloud makes sense not just for compute and services, but also the sheer amount of bandwidth needed to process the amount of data they want to send.
Can it be done a different way? Sure. Will those methods scale to the reach the average user? I seriously doubt it.
1
0
0
fiery
fiery@snac.bsd.cafe
1
0
0
mapto
mapto@masto.bg@troed would it sound better to you if we substitute "requires" with "is easier with"? At least from my point of view this shifts the burden of proof to you.
1
0
0
Troed Sångberg
troed@swecyb.com@mapto It's not like I'm talking about some unknown magic here.
https://social.woefdram.nl/item/a6a9ef48-97a5-40d0-a953-4dafcd367253
0
1
0
Centralization simplifies how thing work in general, especially for end users. You have one place to go where you set up your account and work from single experience. There's a reason why every successful service our there has some level of centralization. It's just easy to use. Ease of use beings in more users which helps the service survive.
Decentralization has some great advantages. But with that comes complexity and with complexity comes a lack of adoption. The lack of adoption means that there's no money in it. And that's great if you're a hobbyist, but not if you're a company.
An easy example is social media. Look at all of the massive services. They are all centralized. Look at a decentralized system like the Fediverse. Yes, it's very decentralized, but the audience is very limited.
Now let's take this back to Signal which was the whole point of the thread. Yes, it has some centralized services. Those centralized services make the system work well enough that average internet users would actually use it. There are decentralized options out there. They work peer to peer so there's no need for things like cloud infrastructure or a big data center to run them. Matrix/Element comes to mind. Super secure, decentralized messaging. Very few people use it because it's just too complicated for the average or even above average user.
So if I'm Signal, a company that wants to build a more secure messaging app, I'm going to make some compromises in order to make it acceptable and palatable to a wide audience so I have a chance to make some money and keep my companhy afloat. Thus, something like AWS makes sense. I can get access to huge resources to handle any user load, but my costs scale in real time with my usage. This is sensible. But there are trade-offs. But i think for what Signal is trying to do, those trade-offs make sense.
1
0
0
fiery
fiery@snac.bsd.cafeNow another point is that non-centralized does not necessarily means peer-to-peer. One such highly successful example is email, which is federated. Yes, most users will just gravitate to some centralized offering like gmail or hotmail, but the system is still interoperable for folks or companies who want more control or even self host. We have options, based on public standards. In that sense even instagram is being more open than signal, in the sense that they now have threads which talk to the fediverse. Signal is openly against any such federation arrangement, thus reducing the power that users have over their own data. They do not even have good export options, arguing that would reduce security. Yet they require a mobile number to sign-up which in most places already doxx the user.
1
0
0
I get only running in one region is a vulnerability. It could be bad engineering…it could also be because of cost. Resiliency isn’t free or necessarily cheap, especially for a company that relies on donations. It’s great that you donate to Signal but I assure you the vast majority of their traffic is sent and received by people who don’t.
I made the point about running in the cloud or on prem because that was part of the pro original post (at least as I remember it…it’s been a while). The email model is essentially peer to peer. It relies on lots of places agreeing on a standard to send messages. The issue with this is that to make that work requires dumbing down the standard and would likely break the goal of an all like signal. Email is not in any way secure. Quite the opposite in fact. Are there ways to make it more secure? Yes. But there is no agreed to standard to do so and thus this feature has not been widely adopted. The way email has gone is to become more and more centralized every day with a handful of companies providing email whose business models do not want secure email. The email market has decided that free is better than secure. The price of free is the provider reads your email to sell your information. I only went down this rabbit hole because Signal won’t want to adopt this model because doing so kills their entire reason to exist. Their compromise is that they handle and procrss the
1
0
0
fiery
fiery@snac.bsd.cafe
0
0
0
boredsquirrel
Rhababerbarbar@tux.socialFair point.
I would say creating a privacy respecting keyboard app would be better then?
Thats like using a #VPN only in the browser, or adding #FreeSoftware apps on a system full of #spyware... doesnt make much sense and you leak more data than you think.
0
0
0
Kevin Karhan 
kkarhan@infosec.space
@Mer__edith To me using #aws shows that you have more #money than #sense and that @signalapp is a #MoneyBurningParty, thus (like #ICQ before) not #sustainable long-term.
- I mean that #MobileCoin #shitcoin doesn't even work so #Signal is too stupid to run a #PumpAndDump #scam wIth 100% pre-mined #shitcoins!
0
1
0
Kevin Karhan
kkarhan@infosec.space
@Mer__edith No.
The fact that @signalapp CHOSE to host the most expensive way possible at a #US military contrator and in spittibgbditance to #CIA & #NSA is so deliberate, it makes #ANØM aka. #OperationIronside aka. #OperationTrojanShield professional by comparison for taking the time and effort to setup shell companies and servers in #Lithuania.
Or to ask bluntly: What Guarantees are there to prevent the #Trump Regime from taking down #Signal once it outlived it's usefulness at skirting #SubshineLaws and #Accountability and #Recordkeeping laws?
- Even if we assume you and all the coders are willing to "choose death over surrendering the keys" or implementing #Govware #Backdoors (which are wholly unnecessary with you demanding #PII like #PhoneNumbers and #Room641A-Style equipment doing the whole #metadata shit)…
If you don't own and physically control the hardware it's run on, the mere existance of #Signal depends on the goodwill of #JeffBezos!
0
1
0
Kevin Karhan
kkarhan@infosec.space
@Mer__edith There are options, it's just that @signalapp is too incompetent to do so (according to your wording) or rather chose not.to take these routes…
- Also you chose to integrate #bloat like #Videocalling and do #centralization instead of proper #PeerToPeer communications!
But since you don't pay me to fix it, it ain't my problem!
- So consider this the worst or best sales pitch. I'm shure you'll be able to tell me in case you actually care, cuz I do!
0
1
0
Kevin Karhan
kkarhan@infosec.space
@Mer__edith So what?
Even if we "justify the bloat" as a form of Escalating Commitment this could've been done better!
How about this: I evidence the opposote for you and I get paid 1% of what I save in billing costs?
Signal wouldn't be the first that I'd help to #CloudExit…
0
1
0
Kevin Karhan
kkarhan@infosec.space
@Mer__edith except @signalapp chose to add that bloat (just like choice was made to add #MobileCoin!) and force it onto your infrastructure instead of doing what even AAA Videogames do and let the users host it…
0
1
0
Kevin Karhan
kkarhan@infosec.space
@Mer__edith again: That isn't magic and if your "#business model" relies on #Azure, #AWS & #GCP, it's inherently and irredeemably flawed to begin with!
- It's a choice to choose a horrible tech stack with extreme lock-in instead of a working & simple system.
Heck, even #Amazon themselves say "#serverless" sucks…
0
1
0
Kevin Karhan
kkarhan@infosec.space
@Mer__edith yeah, that's more of a "You problem" fir @signalapp then...
I'll gladly help in that regard, but not for free!
https://infosec.space/@kkarhan/115492027363018144
0
1
0
Kevin Karhan
kkarhan@infosec.space
@Mer__edith That's why YOU DON'T DO THAT to begin with!
Cuz lets be fundamentally clear on this one: There's no "legitimate reason" to mandate #PII like #PhoneNumbers and have #centralized infrastructure so riddled with #SPOF|s that it can't handle a single datacenter outage.
Seriously, if @signalapp was coded by some freelancer on #Fiverr for like $100 I'd be okay with that. But how many $ did the development and infrastructure cost you (per year)?
To me this is #malpractice!
0
1
0
Kevin Karhan
kkarhan@infosec.space
@Mer__edith yes, and your shitty #App doesn't even run good to begin with.
- Like seriously, for what it's worth @signalapp runs worse and shittier than #WebCall, #Gajim, #monoclesChat, #DeltaChat and #JitsiMeet together!
And I dare you to defend that #Signal needs camera access outside of videocalling!
0
1
0
Kevin Karhan
kkarhan@infosec.space
@Mer__edith No, this is exactly where you got it wrong!
- Tho I'd blame #Moxie and his arrgance building @signalapp instead of you personally.
Also how's that #MobileCoin #Shitcoin going?
- Will it be removed soon or will the #Scam be continued?
Cuz last time I checked #Signal neither cmplied with #MICA nor had any #license for a #MoneyRemittance business in the Eurosystem and @BaFin & @bsi already shutdown the #WorldCoin scam due to way lesser infractions…
0
1
0
Kevin Karhan
kkarhan@infosec.space
@Mer__edith that's the whole problem: You chose to ignore the issues and insted lock-in harder on a garbage tech stack that is not just horribly expensive but in terms of privacy and legal standing more at risk than ever (see #CloudAct) than it should be.
- @signalapp could be way better, but I sincerely doubt that this is ever intended to be done.
Whether that's due to malpractice, incompetence, lazyness or colluding with intelligence agencies is irrelevant for the users.
0
1
0
Kevin Karhan
kkarhan@infosec.space
@Mer__edith not really!
Stop looking for excuses and own.up that @signalapp 's #TechStack is a bat fit for the job!
0
1
0
ItsDoctorNotMrs 🇨🇦
northernlights@mstdn.caThat was unnecessary; I'm interested in their point as well.
1
0
0
David Penfold
davep@infosec.exchange
@northernlights @ElBeeToots @yawnbox
To be fair, he did have a point of sorts.
https://infosec.exchange/@yawnbox@disobey.net/115445851531703933
1
0
0
Kevin Karhan
kkarhan@infosec.space
@davep @northernlights @ElBeeToots @yawnbox
Fact is: @signalapp is run by criminally incompetent Money Burners and whilst @Mer__edith isn't to blame for #Moxie's decisions, she shurely is to blame for not addressing issues and changing course!
- The whole thread at the top is just insulting to anyone who helped companies to do #CloudExit and actually #SelfHost their infrastructure for a fraction of the cost!
0
1
0
David Fetter
davidfetter@kolektiva.social@iwein Did you read literally any part of the thread? Some people will choose low reliability, high latency, and low availability so they can attempt decentralization. Some people will also become hermits. It's about the same proportion of people.
0
0
0
David Fetter
davidfetter@kolektiva.social@lexinova OK, let's go. You're the one making the positive claims, so the burden of proof is on you.
First sine qua non for your claim: Is Mastodon using a reliable protocol? If so, please point to a formal description of it, or describe it, whichever you like.
0
0
0
Old Man in the Shoe
jenzi@mastodon.social@lexinova @davidfetter would love to hear it too, how mastodon can be applied to signal, please
1
0
0
Kevin Karhan
kkarhan@infosec.space
@jenzi @lexinova @davidfetter Doesn't even need that.
#XMPP+#OMEMO (Chats) & #P2P-#WebRTC (Video- & VoiceCalling) are evdently better than a centralized, #SingleVendor & #SingleProvider system…
- And that is why @signalapp will inevitably end like #ICQ & #Skype!
0
1
0
FinchHaven sfba
FinchHaven@sfba.social
1
0
0
Kevin Karhan
kkarhan@infosec.space
@FinchHaven @yawnbox @davep except @signalapp chose to use #AWS (and @Mer__edith chose to not migrate away from it) as well as #Signal chose to bloat from #TextMessaging to centralized #VideoCalling.
There are better options and even if Signal refused to #decentraloze they could've easily outsorced the most workload to users with #P2P #WebRTC.
If people accept nonexisting dedicaded Servers for AAA FPS games sold for $60+, then they certainly can deal with P2P videocalls in a "Free"* App…
Free as in: Relying on big donations because the people behind it can't even do a #Shitcoin #Scam properly...
0
1
0
ArneBab
ArneBab@rollenspiel.social@wanwizard And there are ISPs with IPv6 whose addresses cannot be accessed from outside the ISP.
That’s why we cancelled a fiber plan here: we found out that half the people wouldn’t be able to connect via IPv6, and there was no IPv4 at all.
It seems that they fail badly on their peering.
@davep @yawnbox
1
0
0
Kevin Karhan
kkarhan@infosec.space
@wanwizard @davep @ArneBab @yawnbox even my #ISP won't give me proper #DualStack, so I'm stuck on static #IPv4 only…
0
1
0
ArneBab
ArneBab@rollenspiel.social@wanwizard I don’t even need fixed IPv4. I have a dyndns address.
1
0
0
WanWizard 🏴 🇳🇱
wanwizard@mastodon.scot
1
0
0
David Penfold
davep@infosec.exchange
@wanwizard @ArneBab @yawnbox We have that on our backup 4G network, but that's normal really.
1
0
0
WanWizard 🏴 🇳🇱
wanwizard@mastodon.scot@davep @ArneBab @yawnbox Normal as in "we've gotten used to it", yes.
But definitely not normal. It is technically not an issue to give every mobile connection a publicly reachable IPv6 address, it is what it is designed for.
CGNAT is one of the things that makes both ISPs and hosting parties lazy, there is still plenty out there that is IPv4 only.
I often see surprised faces when I discuss our hosting services with potential clients, and I mention that we run full dual stack everywhere.
1
2
0
Kevin Karhan
kkarhan@infosec.space
@wanwizard @davep @ArneBab @yawnbox IMHO #CGNAT should've been outlawed and #IPv6 support should've been mandated by law...
- But that's beyond the point…
0
1
0
David Penfold
davep@infosec.exchange
Things may have moved on since then, "attest: Functionality for remote attestation of SGX enclaves and server-side HSMs."
1
0
0
Kevin Karhan
kkarhan@infosec.space
@davep @ArneBab @dryak yeah, the same #proprietary shitboxes thar get hacked so often.that #Intelcyeeted that from #Consumer #CPU|s and now there's no "legal" way to play #4K #BluRayDisc|s on modern systems.
Moxie trusts too much into the silicon of parties who's goals are irreconcileable at odds with his demands.
But I guess that's normal with @signalapp folks…
https://infosec.space/@kkarhan/114935952643402592
https://infosec.space/@kkarhan/115492122419368937
https://infosec.space/@kkarhan/115492154062048948
0
1
0
ArneBab
ArneBab@rollenspiel.social@scatty_hannah I fully agree.
I’m always happy when parent’s groups at school use #Signal, because then we at least have reliable encryption and communicate outside the Meta/MS/Apple/Google walls.
And I have Signal Desktop, so I can actually contribute from the device I’m most comfortable with.
CC @Mer__edith to say: THANK YOU!
1
0
0
Kevin Karhan
kkarhan@infosec.space
@ArneBab @scatty_hannah @davep @yawnbox @Mer__edith not really outside given the dependency on #aws that @signalapp allegedly has.
Just like a meeting isn't ouside of some GAFAM HQ because it happened in a bathroom stall and not a conference room!
https://infosec.space/@kkarhan/114935952643402592
1
1
0
zaire arcana
soop@outerheaven.club@davep @yawnbox @Mer__edith Bandwidth would not be an issue I’m fairly certain.
1
0
0
David Penfold
davep@infosec.exchange
@soop @yawnbox @Mer__edith Latency is the issue, not bandwidth.
1
0
0
DrYak
dryak@mstdn.science@davep @yawnbox @Mer__edith Regarding Tor: instant messaging (if you stretch "instant" to cover several seconds which is acceptable in practice) have been successfully ran over Tor and other distributed settings.
Regarding video not relying on a centralized infra: Skype during its Kazaa-/pre-Microsoft- era and its "Super nodes" has been a widely successful example of a video calling software that doesn't rely that much on centralisation (but of course with a completely different security model)
2
2
0
DrYak
dryak@mstdn.science@davep @yawnbox @Mer__edith (note: I am not saying that Signal is bad. Merely jumping in about centralisation. I actually appreciate Signal, e.g., unlike the above example of Skype, it is tolerating 3rd party open source clients, so people like me who neither run Android nor iOS on the smartphone can still communicate with friends).
0
0
0
Kevin Karhan
kkarhan@infosec.space
@dryak @davep @yawnbox @Mer__edith yes, cuz.I've been using #XMPP (#OTR, now #OMEMO) for 15+ years over @torproject / #Tor on a THROTTLED #EDGEland* connection!
- It's just that @signalapp chose #centralization over #sustainability…
*#Germany is EDGEland
0
1
0
Tris
tris@chaos.social@yawnbox @Mer__edith There's @cwtch which uses Tor for routing. All good except... it's P2P xD
1
0
0
Kevin Karhan
kkarhan@infosec.space
@tris @yawnbox @Mer__edith @cwtch granted, @signalapp chose to be bad!
- As in: It's easer, faster, cheaper, more resilient, private and secure to onboard #TechIlliterates woth #XMPP+#OMEMO over @torproject / #Tor using @guardianproject #Orbot @monocles / #monoclesChat than to do so for #Signal for the last 15+ years !
0
1
0
mapto
mapto@masto.bg@davep @yawnbox @Mer__edith with decentralization you're throwing out of the window not only latency, but often also the capacity to guarantee delivery.
Consider this talk for details:
https://hapyyr.com/@bogo/115401249466782443
...also for alternatives to Signal and the corresponding tradeoffs.
1
0
0
Kevin Karhan
kkarhan@infosec.space
@mapto @davep @yawnbox @Mer__edith that is dangerous #disinfo, cuz you can let clients send back sending confirmation.
- Worked for me for 15+ years!
1
1
0
The problem is that social software and instant messaging are heavily state-dependent—which Tor is not, and its state management and persistence issues are much smaller.
1
2
0
Tinkerer
tinkerer@ieji.de@yawnbox @Mer__edith I think for audio and more so for video it is not possible and a massive infrastructure like AWS is needed. Session messenger which is decentralized is still in beta (since some years) for audio calls, also considering that they don't have nearly as many users as Signal.
2
0
0
Kevin Karhan
kkarhan@infosec.space
@tinkerer @yawnbox @Mer__edith not really.
Just offload it to the users - if it works for AAA FPS then it works for videocalls!
1
1
0
Tinkerer
tinkerer@ieji.de@yawnbox @Mer__edith Signal is doing the more realistic thing to do. And putting all this effort in e2ee and lately in PQ is a way to mitigate the fact they are using a corporate infrastructure that is of course besides the benefits of secure messaging.
1
0
0
Tinkerer
tinkerer@ieji.de@yawnbox @Mer__edith Signal's tactics are needed for mass adoption of secure messaging. The phone numbers thing is quite useful and the drawbacks are not so bad as described (also now usernames can be used).
0
0
0
Andromxda 🇺🇦🇵🇸🇹🇼
Andromxda@infosec.space@yawnbox Moxie is opposed to federation because he tried it out and saw how terribly it failed. Decentralized protocols are unreliable. Just look at Matrix, it's buggy as hell. Even Mastodon (ActivityPub) constantly has several federation issues, but it's not as bad because no one really depends on it. Social media isn't as critical as instant messengers.
There's a reason why no decentralized messenger has taken off.
1
0
0
ArneBab
ArneBab@rollenspiel.social@kkarhan I did not say outside Amazon …
The dependency on AWS means that we spill who talks to whom and when (the AWS owner can figure that out with timing attacks), but the content is off limits.
Having reliable encryption is already a big deal.
1
0
0
David Penfold
davep@infosec.exchange
@kkarhan @mapto @yawnbox @Mer__edith
"It's easer, faster, cheaper, more resilient, private and secure to onboard #TechIlliterates woth #XMPP+#OMEMO over @torproject / #Tor using @guardianproject #Orbot @monocles / #monoclesChat..."
If it's easier, why isn't it as successful and used by the military etc? You seem to have dismissed video calls etc too. You could argue against that functionality for certain use cases, but it's become a core part of secure messaging over time. Maybe they just have different audiences.
I kind of agree on Moxie's reliance on Intel SGX though. Even at its inception it worried me. But it's not part of the core E2EE protocol so could potentially be replaced.
1
1
0
Tinkerer
tinkerer@ieji.de@kkarhan @yawnbox @Mer__edith nope... in AAA FPS it is a totally different deal... Signal uses the most secure encryption protocol (publicly known) and tries to get the best performance possible. Also if Signal SOMEHOW offloads this to the users (their devices), by some decentralized/meshing communications scheme you will be complaining about extreme battery drain among other disfunctions...
1
0
0
Kevin Karhan
kkarhan@infosec.space
@tinkerer @yawnbox @Mer__edith well, that's an edge-case cuz if someone expects to host a conference call on EDGE speeds they're utterly deranged.
Cementing my argument that @signalapp made themselves the #SinglePointOfFailure.
- Whereas if @monocles were to close (which they don't but lmfor the sake of example!) that wouldn't impact #eMail, @nextcloud and #XMPP+#OMEMO beyond the users having to migrate their accounts…
0
1
0
Kevin Karhan
kkarhan@infosec.space
@davep @mapto @yawnbox @Mer__edith Granted #MIL / #INTEL - espechally in the #USA - have bespoke pipelines (they tend to use @RocketChat ) and for #Videocalling there are many #WebRTC based options like #WebCall & #JitsiMeet …
- USE THE RIGHT TOOL FOR THE JOB!
You don't expect a Motorcycle to be good at hauling trailers nor do you expect a 40t truck to be perfect for cruising around mountain passes.
0
1
0
flossifatal598
flossifatal598@mastodon.social@janvlug @Mer__edith Linux mobile userspace APIs is almost non-existant: no standardized push notification, no app lifecycle, no background app policy, no clear sleep/standby/dose policy, no call/ring system, no modern mobile-like audio routing system, etc.
We absolutely need Mobile Linux to succeed but we first need a working modern userspace before we can ask anyone to make apps for it (especially apps as complex as Signal with call, notif, background activity, etc.)
1
0
0
pixelschubsi
pixelschubsi@troet.cafe@flossifatal598 @janvlug where have you lived the last 10 years? we have @unifiedpush, we have Flatpak app lifecycle, we have background and idle inhibit portal https://flatpak.github.io/xdg-desktop-portal/docs/doc-org.freedesktop.portal.Background.html https://flatpak.github.io/xdg-desktop-portal/docs/doc-org.freedesktop.portal.Inhibit.html, we have pipewire for modern audio and video routing.
0
1
0
fcat
f@ieji.de@Mer__edith You're forgetting about, say, GrapheneOS or Linux there. I would guess that many of the users who are concerned about this don't rely on Big Tech OS....
1
0
0
Meredith Whittaker
Mer__edith@mastodon.world@f true, but at least some of their interlocutors almost certainly 'rely on big tech' OS's, so they still need to care.
0
0
0
flaeky pancako
fleeky@prsm.space@Mer__edith
https://keet.io/
https://docs.pears.com/
uses only edge devices as infra , does voice / video / txt / application distribution via hash urls, solved multi device identity in a p2p space , has search , no limits on file sharing , scales like bitorrent can do ip obfuscation via blind peers, has a whole ass software ecosystem that grows by the day.
it has bugs but it is amazing how well it works and i would say it's ready for scale up.
1
0
0
0
0
0