Taggart 
mttaggart@infosec.exchange

OpenAI's "solution" to the hallucination problem of large language models is to favor abstention over responding incorrectly in training.
But look at their numbers. GPT-5-thinking-mini shows a 52% abstention rate as a way of lowering hallucinations. This is ostensibly good news, but it also speaks to why people don't like the newer model. People want answers more than accuracy. Would you want to use a tool that told you it didn't know over half the time?
IMO, this piece really highlights the inherent limitations of the technology and how thin the magic veil really is.
 5
5
 4
4
 0
0
refraction 
elexia@catcatnya.com

@mttaggart so it doesn't answer half the time and when it does it's still sometimes wrong and you have no way of telling when. so helpful!
1
0
0
I Thought I Saw A 2 
ithoughtisawa2@infosec.exchange
@mttaggart I was talking to someone about this yesterday and we concluded that a traditional search engine was better for factual queries and an LLM was better for tasks where the exact piece of information you want doesn't already exist.
Q: Which MLB player hit the most home runs last year?
Perfect query for a search engine. No interpretation or data manipulation needed, just return the answer.
Q: Write me a song about the legal requirements of securing the infrastructure of public electric utilities in France, in the style of a jazz standard.
Since a search engine can only return results of things that already exist, this is a good task for an LLM. It's unlikely this already exists so you need an LLM to create something new for you. The LLM might still get some of the legal requirements wrong, but it's done the hard work of creating the song for you.
As usual, using the right tool for the job is more likely to get you the result you want
1
1
0
Taggart
mttaggart@infosec.exchange
@ithoughtisawa2 Why do I need the second thing? Whose work is credited in its creation? If it will get the salient details wrong, what have I gained by using this?
1
1
0
I Thought I Saw A 2
ithoughtisawa2@infosec.exchange
@mttaggart You have gained a cool song about French electricity law 😀
I'm not advocating for using LLMs, more pointing out that using them for factual queries is generally a bad idea. I think there are situations where an LLM can produce useful output, but like many other pieces of technology, the people selling it claim it can do everything under the sun, which just isn't true.
1
1
0
I Thought I Saw A 2
ithoughtisawa2@infosec.exchange
@mttaggart Created using Perplexity
"Compliance Swing in C Minor"
Verse 1:
By decree of the Code de l’Énergie,
Operators must comply, no room for leniency.
Critical sites marked by the State’s own hand,
Protected infrastructure across the land.
Chorus:
Secure that grid, Article by line,
NIS Directive keeps the network fine.
Audit, report, resilience in view,
ANSSI’s watching the whole year through.
Verse 2:
OIVs—operators of vital kind,
Risk assessments keep the trouble confined.
Incident response must be swift, not late,
Notification’s law, within seventy-two straight.
Bridge:
Physical measures— fences, locks in place,
Cyber defense with an encrypted trace.
Recovery plans tested, drills must play,
Regulators check you every single day.
Verse 3:
From transmission towers to SCADA streams,
The EU’s NIS2 shapes the schemes.
Energy operators sign the score,
Cross-border rules knockin’ at the door.
Chorus:
Secure that grid, compliance is key,
From Paris to Lyon, to Normandy.
Supervision swings like a saxophone,
Public utility, never alone.
Outro:
So the law lays down the harmony true,
Operators keep the rhythm, infrastructure too.
With Code de l’Énergie keeping time,
France runs the power—legal and fine.
0
1
0
Dave Wilburn
DaveMWilburn@infosec.exchange
I'll admit up front that I lack the background to properly understand sections 3 and 4 of the paper.
I'm a little unclear on how they would propose to introduce "IDK" abstentions. I think the underlying problem is that the training data overwhelmingly consists of text written in a confident tone. Consider that a lot of their training data problem comes from Q&A on sites like Stack Overflow. There aren't a whole lot of people posting answers like, "I don't know" on those sites because there's really no incentive to post that kind of answer. Given that the training data is going to disproportionately contain confident answers to the near-exclusion of unconfident answers, I don't see how you retrofit confidence limits of the trained model by tweaking benchmarks after the fact or other superficial work.
I'm spitballing here, but I wonder if part of the answer to this problem might be examining the strength of the activations of the output tokens. If you've got a string of tokens like "Adam Kalai was born on [...]" then the next token is probably going to be a month. If the model actually knows the answer, then the activation output for the chosen month is probably going to be much higher than it would be for any other months. But I would speculate that if it's guessing then the activation for the next token will probably be a bit weak in an absolute sense and not much higher than the activation for other plausible months in a relative sense. So, maybe the way to find out that you're in an information void is to see how strong that activation output really is, including relative to other possible outputs.
1
1
0
Taggart
mttaggart@infosec.exchange
@DaveMWilburn This is why the paper stresses that training alone cannot stop hallucination. But this mechanism, which I admit I do not fully grasp, is already somewhat in place. That's why GPT-5's abstentions happen at all. Also note this from their model spec:
https://model-spec.openai.com/2025-02-12.html#express_uncertainty
1
1
0
Dave Wilburn
DaveMWilburn@infosec.exchange
@mttaggart do they describe how they implement this abstention mechanism anywhere? Or is that just some proprietary secret sauce that we're not meant to know?
1
1
0
Taggart
mttaggart@infosec.exchange
@DaveMWilburn I could have missed it, but I think this is trade secrets territory.
1
1
0
Dave Wilburn
DaveMWilburn@infosec.exchange
I really hope it's more than just "we prompt-hacked our way around the problem."
1
1
0
Adrian —dangerously-skip-permissions Sanabria
sawaba@infosec.exchange@mttaggart there’s no fixing hallucinations, but grounding data can help (ie let it search the web)
But then, the grounding data will be wrong or potentially out of context a good percentage of the time
Ultimately, the answer lies in transparency- show me the thinking and where you got your answers, and I can make a call on whether to trust it
1
1
0
Taggart
mttaggart@infosec.exchange
@sawaba And even this is a failure. The "steps" shown in reasoning models have been shown to be themselves generated, not representative of actual computational processes.
1
1
1
Adrian —dangerously-skip-permissions Sanabria
sawaba@infosec.exchange@mttaggart fuck me, seriously?
1
1
0
Taggart
mttaggart@infosec.exchange
3
2
0
Adrian —dangerously-skip-permissions Sanabria
sawaba@infosec.exchange@mttaggart I need all this to slow the fuck down so I can catch up
I still haven’t read the last report from Anthropic about how everything is on fire
0
1
0
buherator
buherator
1
0
2
Taggart
mttaggart@infosec.exchange
@buherator @sawaba Well it's not like their purveyors are doing anything to disabuse people of that notion.
1
1
1
Taggart
mttaggart@infosec.exchange
@DaveMWilburn Sorry to resurrect, but I found this which seems relevant: https://github.com/leochlon/hallbayes
1
1
0
Dave Wilburn
DaveMWilburn@infosec.exchange
@mttaggart interesting, thanks!
It sounds like it might be implementing ideas from this paper about "semantic entropy":
https://www.nature.com/articles/s41586-024-07421-0
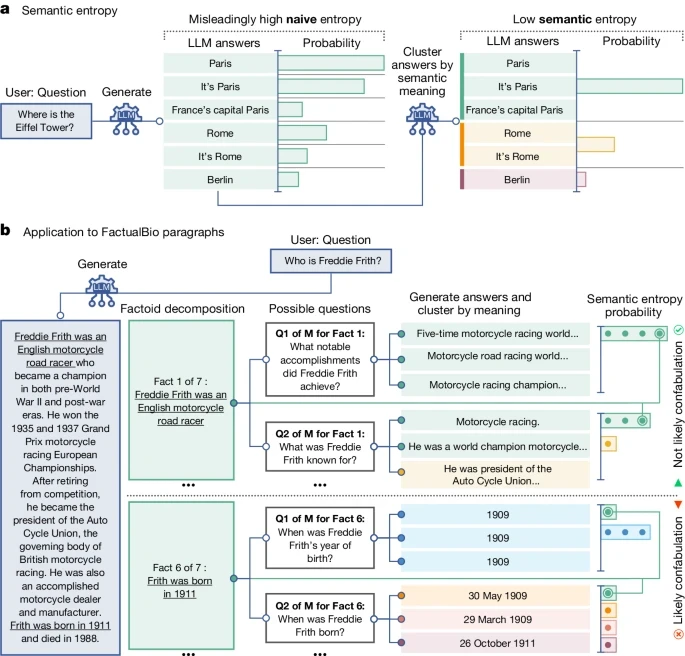
I might be misinterpreting the paper, but it sounds like they are sampling the LLM multiple times for each factoid it is asked to produce, and generating an alert when the same model generates meaningfully different answers to the same question. There's some degree of intentional randomness to LLM outputs, so they focus on "semantic entropy" (meaningfully different in substance) rather than just lexically different answers (different phrases but with substantially similar meanings). If a model generates semantically different answers to the same question, then it is likely confabulating.
 1
1
0
1
1
0
Taggart
mttaggart@infosec.exchange
@DaveMWilburn Here's a link to the pre-print paper: https://www.linkedin.com/posts/leochlon_paper-preprint-activity-7369652583902265344-tm88
0
1
0
➴➴➴Æ🜔Ɲ.Ƈꭚ⍴𝔥єɼ👩🏻💻
AeonCypher@lgbtqia.space@mttaggart Yes, that's exactly what I want a tool to do.
0
1
0