Will Dormann
wdormann@infosec.exchange
Ivanti CVE-2025-22457 is being exploited ITW.
https://forums.ivanti.com/s/article/April-Security-Advisory-Ivanti-Connect-Secure-Policy-Secure-ZTA-Gateways-CVE-2025-22457
Per Mandiant:
We assess it is likely the threat actor studied the patch for the vulnerability in ICS 22.7R2.6 and uncovered through a complicated process, it was possible to exploit 22.7R2.5 and earlier to achieve remote code execution.
Gee, who could have imagined that attackers are looking at patches? 🤔
1) This apparently was silently fixed for ICS in 22.7R2.6, as the fix for this was released in February. Per Ivanti, the buffer overflow was considered a "product bug" at that time, as opposed to a vulnerability. Ivanti Policy Secure and ZTA gateways are expected to receive a patch in late April.
2) The advisory still conveys the magical thinking if if your device shows signs of compromise, then you should perform a "factory reset." This is magical in that the ICT won't catch a compromise nor will the "factory reset" reset to factory condition if the attacker is bothering to try.
While Mandiant also parrots the magical thinking of running the ICT tool, which I guess is the best advice if you're not going to throw the device in the trash since there isn't an official integrity checking tool that is sound, they do throw out a tidbit of:
... and conduct anomaly detection of client TLS certificates presented to the appliance.
Bets on whether CVE-2025-22457 is an overflow in the handling of a field in a client-provided certificate? 😂

 3
3
 3
3
 0
0
Will Dormann
wdormann@infosec.exchangePlease ask the device to reset itself to factory state, and believe it when it tells you how it went.
😂
0
1
1

Will Dormann
wdormann@infosec.exchangeGiven that the web server on an ICS runs as the limited nr user, both the Ivanti and the Mandiant advisory are missing any indication whatsoever how the threat actors are gaining root privileges. And the CVSS score for CVE-2025-22457 is definitely wrong, as it has S:C (scope changed). The LPE is what will change the scope, but the April Ivanti advisory lacks any mention at all about any LPE. But I suppose it's common practice to assign CVSS scores to a single CVE that's used in a multiple-vulnerability attack chain. 😕
I've reported 4 different ICS LPEs to Ivanti recently, but none of them have been fixed yet.
Back in the CVE-2025-0282 days, Ivanti made up a CVE-2025-0283 CVE to capture the LPE aspect of attacks happening in the wild. I say "made up" because I've seen no evidence whatsoever that any LPE was fixed between 22.7R2.5 and 22.7R2.6.
Knowing what's going on in an ICS device is a huge blind spot, but apparently seeing how attackers are LPE'ing is even blind-er.
1
2
0
Will Dormann
wdormann@infosec.exchangeNow, regarding the "silent fix" of CVE-2025-22457, which per Ivanti:
This vulnerability has been remediated in Ivanti Connect Secure 22.7R2.6 (released February 11, 2025)
That word remediated...
Careful readers will see that it's not clear whether Ivanti fixed the vulnerability in 22.7R2.6.
What changed in 22.7R2.6? With this version, Ivanti compiled some of the ICS binaries with exploit mitigations that have been around for 20 years. And wouldn't you know it, it paid off already? Everybody's gotta learn sometime...

 2
2
0
2
2
0
pejacoby
pejacoby@infosec.exchange@wdormann really enjoyed their phrasing of “oh it was just a BUG when we fixed it in February, seems as though it’s suddenly become a VULNERABILITY… oopsie!”
1
1
0
Will Dormann
wdormann@infosec.exchange@pejacoby
They seem to have a history of... How do I phrase it... Not embracing the truth? 😂
0
1
0
Will Dormann
wdormann@infosec.exchangeAnd per the excellent folks at watchTowr, we can see what the vulnerability is:
A stack buffer overflow in X-Forwarded-For
No need to find a specific endpoint or do something clever. Simply make a web request to anywhere on an ICS system with a large X-Forwarded-For HTTP header and you'll get a stack buffer overflow on the system. 🤦♂️
And due to the fact that the Ivanti web server does a fork() without a corresponding exec(), we get the same memory layout every single time.
Now, about Ivanti's use of remediated... The function where the overflow happens just happens to have been rewritten in a way that avoids the overflow.
Did Ivanti recognize the possibility of a stack buffer overflow and not recognize it as a security issue? Or did they just happen to change code to accidentally avoid the overflow (and decide to use exploit mitigations as well).
You decide...



 3
5
0
3
5
0
Graham Sutherland / Polynomial
gsuberland@chaos.social
@wdormann so presumably `s` in the vulnerable code is a fixed sized stack buffer, which is getting overflowed due to the input size being constrained only by the return value of strspn? (the linked post didn't seem to explain this either)
1
0
0
Will Dormann
wdormann@infosec.exchange@gsuberland
If you look at where exactly the crash happens with a large-enough X-Forwarded-For header, it's when a value is set to -1 after the strlcpy.
Specifically, here in the disassembly.
If you play with the buffer size, you can get the segfault to occur in a few other places, which is what I assume attackers ITW are doing.
 1
0
0
1
0
0
Graham Sutherland / Polynomial
gsuberland@chaos.social@wdormann right, and since edx is loaded from a pointer stored in the stack you at least get a "write -1 where" bug with an address restricted by the specified character list, or probably more if you can make that not crash.
but where is the stack buffer overflow actually occurring? from the limited info in these screenshots (I don't have the firmware), I presume that `s` is a fixed size stack buffer, yes?
2
0
0
Graham Sutherland / Polynomial
gsuberland@chaos.social@wdormann or v117, I suppose, although if that first call was trashing the stack frame I'd expect the next strlcpy call to blow up
0
0
0

Graham Sutherland / Polynomial
gsuberland@chaos.social@wdormann so is v193 in the second screenshot also a stack buffer? if so, lmao
1
0
0
Will Dormann
wdormann@infosec.exchange@gsuberland
Yes, in the remediated version of the code v193 is a fixed-size array of 3.
 1
0
0
1
0
0
Graham Sutherland / Polynomial
gsuberland@chaos.social@wdormann ahhhh, gotcha. so the stack still gets smashed but the guard protection catches it. what a crap fix lol
1
0
0
Will Dormann
wdormann@infosec.exchange@gsuberland
Actually, no.
I've not seen any crash on a 22.7R2.6 system.
I think there's other checks in place to prevent that snippet of code from being reached.
1
0
0
Graham Sutherland / Polynomial
gsuberland@chaos.social@wdormann oh weird. any signs that they're building with optimisations off and it just didn't eliminate the dead function? (given the quality of the code, it would not surprise me if they ran with -O0 due to UB)
1
0
0
Will Dormann
wdormann@infosec.exchange@gsuberland
Eh, I haven't seen any obvious signs that it is -O0.
Is there an easy way to check for this other than looking at lots of functions with my eyeballs? 😂
1
0
0
Graham Sutherland / Polynomial
gsuberland@chaos.social@wdormann for gcc one tell is if you dig through a few short functions with no locals or outbound calls (sort by function size is an easy method) and find that they all push a stack frame (push ebp; mov ebp, esp) at the start, then it's probably -O0. this is true with -fstack-protector enabled or disabled. as soon as you go to -O1 it'll start eliding the frames when they're unnecessary, absent additional flags to force them.
1
0
0
Will Dormann
wdormann@infosec.exchange@gsuberland
Thanks.
No, I see no evidence of -O0 in the web binary using that tell.
1
0
0
Graham Sutherland / Polynomial
gsuberland@chaos.social@wdormann interesting. who knows what they're up to, then. at least they turned the protections on even if their code is still garbage. good time to go hunting for logic bugs.
2
0
0
Will Dormann
wdormann@infosec.exchange@gsuberland
Only took them about 20 years to figure out that exploit mitigations are a good idea. 😂
0
0
0
Will Dormann
wdormann@infosec.exchange@buherator
I mean, this would be discoverable with the dumbest of dumb HTTP fuzzing.
You'd need to know absolutely nothing about the target app or what it expects.
1
1
0
Will Dormann
wdormann@infosec.exchange@gsuberland
Now that I look with a debugger, we can see that both the vulnerable and the post-remediation versions end up doing a strlcpy (with an attacker-controlled size) to a fixed-size buffer.
With the vulnerable R2.5 version, we can see some immediate evidence of badness (in my case a partial EIP overwrite with the ascii 1 characters we used in our buffer).
However, in the "remediated" R2.6 version, we can still see a fixed-size buffer that is overflowed with the attacker-provided-size buffer. However, in the "remediated" version of ICS, the overflow doesn't seem to result in a crash or other subversion of anything.
🤔

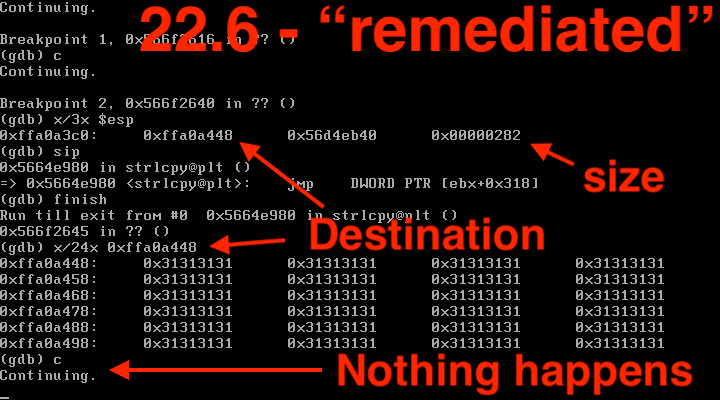 1
0
0
1
0
0
Graham Sutherland / Polynomial
gsuberland@chaos.social@wdormann is there another large stack buffer in the same frame that's just happening to eat the overflow, leaving the return pointer unclobbered? easiest way to tell would be to dump the full stack contents between ebp and esp just before the function epilogue where the old frame is restored.
1
0
0
Graham Sutherland / Polynomial
gsuberland@chaos.social@wdormann also if you can make the header value longer without tripping up Requested Entity Too Large or hitting other artificial limitations in the buffer that'd be worth testing
another thought: what happens if you include the same header twice? if global values get broken by the first call through, but then end up not being touched because you're not calling back into the same code, you might be able to break things with a double header trick (not for stack stuff obviously though)
1
0
0
Will Dormann
wdormann@infosec.exchangeIf I look closer at the difference between the vulnerable version and the "remediated" version, it's now clear where the fix is.
In the vulnerable code, the attacker-provided length of data is strlcopy'd into a 50-byte array. And badness ensues.
In the "remediated" version, the strlcopy only copies 50 bytes, as the target variable is 50 bytes.
So I'd consider this an actual fix. But presumably Ivanti didn't realize that a stack buffer overflow could have a security impact? And thus the lack of CVE when it was fixed, or the attempt to also fix their Ivanti Policy Secure and ZTA Gateways products? 🤷♂️

 1
3
0
1
3
0
Will Dormann
wdormann@infosec.exchange
1
0
0
Graham Sutherland / Polynomial
gsuberland@chaos.social@wdormann what's happening with that first strlcpy to v194 though?
1
0
0
Will Dormann
wdormann@infosec.exchange@gsuberland
In the updated code, the v194 gets used as an input for the 2nd bounded strlcpy and also as an input for inet_aton()
If I am to believe IDA, that v194 is 3 bytes long, but I'm not sure that I believe it. And I've not been able to trigger any sort of crash using any sorts of inputs.
 1
0
0
1
0
0
Graham Sutherland / Polynomial
gsuberland@chaos.social@wdormann in the screenshot you showed before it was three DWORDs long (12 bytes) which is still too short, so yeah, bit weird.
although given that decomp it looks like it's maybe just passing a pointer from the stack, rather than a buffer? and that would explain why IDA thought it was DWORD-shaped. under debug does it look like the address being passed into the first strlcpy is on the heap rather than the stack?
1
0
0
Will Dormann
wdormann@infosec.exchange@gsuberland
Ah, right. DWORDS. Not bytes. 🤦♂️
But yeah, still an odd amount of storage for an ASCII IP address.
The destination of the first strlcpy in the updated code is a stack address.
 1
0
0
1
0
0
buherator
buherator1) APTx runs its dumbest fuzzer and writes an exploit
2) ???
3) Ivanti releases a patch
4) APTx notices their bug is burned
5) APTx goes for a aggressive campaign (or passes the exploit to low-end peers) to cash in on the patch gap.
6) Threat intel picks up ItW exploitation
With my previous comment I wanted to express my worry that we are probably in stage 2) with God knows how many Ivanti 0-days right this moment.
2
1
6
Will Dormann
wdormann@infosec.exchange@buherator
Yeah, the funny/scary thing about all of this is that these recent cases were all based on "we saw that the device was compromised by the failed ICT test"
That right there is evidence that the attacker was SO BAD that they didn't even bother to hide their tracks. Imagine what the good ones are up to. 😂
Yes, the same thing could be said for any attack, but the Ivanti case is somewhat special based on how trivial it is to subvert both the external ICT and also the factory reset process.
1
1
1
MasterOfNinurna
MasterOfNinurna@infosec.exchange@wdormann With recent CVE-2025-22457 there finally is a turning point reached. "Older" devices like PSA3000 get no new updates and Ivanti actually force customers to buy new devices for bugs (or security flaws) which are so obvious that it is a wonder they were not detected sooner. In the last days we broke our head how to react to this mess and for us the only logical approach would be putting the Ivanti SSL VPN device behind an additional security factor. This could be OpenVPN or Wireshark but this would mean too much overhead. I think we found a better solution and maybe this is of interest for some people. We simply present visitors a web site (instead of Ivanti login page) where they have to enter a single password. If they enter it correctly the firewall behind it adds rules for the visitor IP. This approach completely hides the SSL appliance from the outside. It is not possible for an attacker to detect the device and not possible to reach it. This approach could also work for any other SSL VPN device. We also considered switching to other manufacturers but found out that they have similar security issues because when you run a SSL VPN service in public internet you perse have a golden honeypot which attracts a lot of (mostly chinese) bees. Enough talking. Here is the software : https://github.com/Vinylrider/ivantiunlocker
0
1
0
Will Dormann
wdormann@infosec.exchangeIf we poke around with various sizes/contents of the buffer that we send, we can conclude that we can indeed control EIP. (Yes, EIP, since web is a 32-bit app 😂).
However, given that the address space of web has nothing that matches up with ASCII-based number/. addressing, I'm curious what these "sophisticated means" being used ITW are. Maybe something data-based? 🤔
Also LOL at Ivanti's:
it was evaluated and determined not to be exploitable

 2
2
0
2
2
0
Ron Bowes
iagox86@infosec.exchange@wdormann can you do a partial overwrite to replace the first, second, or third address bytes and wind up somewhere interesting?
Failing that, you probably need to overwrite something else on the stack
1
1
0
Will Dormann
wdormann@infosec.exchange@iagox86
Yeah, I can do an overwrite of the last two bytes of the return address. Eg with 00nn or just the last byte with a fixed 00. (00 part due to the trailing null byte)
Nothing jumped out at me as super interesting, but I may give it another look.
0
1
0
Will Dormann
wdormann@infosec.exchangeRapid7 has provided details and a PoC for how to exploit this:
https://attackerkb.com/topics/0ybGQIkHzR/cve-2025-22457
TL;DR: Since you can't steer EIP to something you control directly, you do a heap spray and go the indirect route of a non-limited EIP subversion.
1
2
0
Will Dormann
wdormann@infosec.exchangeFWIW, I cannot reproduce the Rapid7 PoC. Per the R7 write-up, they can get around the limitation of only addressing things in the 0x30303030 - 0x39393939 address space (including 0x2e2e2e2e) by doing a heap spray.
But at least in my naive testing on a single VMware VM that I have handy, I cannot get the heap spray to get anywhere near that address range. For me, the spray starts pretty consistently around the 0xcnnnnnnn range.
As such, while the heap spray is indeed succeeding at placing known bytes at guessable locations, the fact that these allocations happen at higher than reachable memory locations makes the heap spray accomplish nothing.
...
1
1
0
Will Dormann
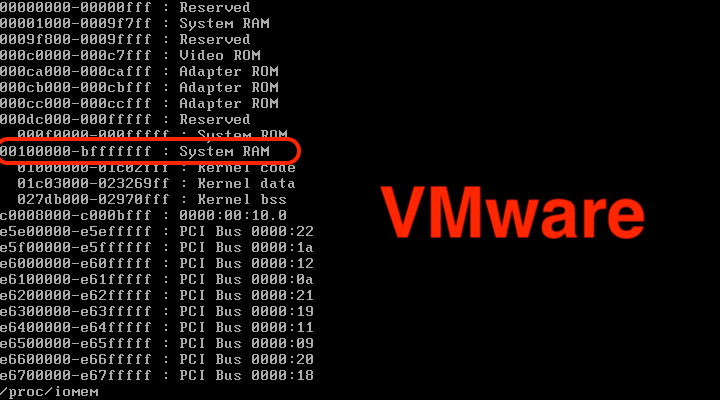
wdormann@infosec.exchangeWhy am I seeing a difference with my heap allocation addresses vs. what Stephen is seeing?
"Easy"
I'm using VMware, and Stephen is using Hyper-V.
Looking at the e820 info when the VM boots, we can see that with a VMware VM, we have a couple of ACPI entries, and then the usable section after that starts at 0xbff00000. With Hyper-V, there is no ACPI section, and the usable section merely starts at 0x00100000. Also looking at the /proc/iomem output, we can see a clear difference between memory layout in a Hyper-V VM vs. a VMware VM.
What are the consequences of this?
An ICS VM that is running on a default VMware configuration will presumably not be exploitable using the Rapid7 technique. However one running on Hyper-V will be. 🤔
Edit All of the above is a red herring, as I don't know how computers work.


 2
2
0
2
2
0
Caitlin Condon
catc0n@infosec.exchange@wdormann Hey thanks for this! Stephen's out of office for the next couple weeks, but happy to flag when he's back to see if there's anything we can do.
1
1
0
Will Dormann
wdormann@infosec.exchange@catc0n
I've been DM'ing with him on the Bad Site. So I think we're good. 😀
1
1
0
Will Dormann
wdormann@infosec.exchange@killminusnine
If you use VMware on a Windows system with HVCI enabled, VMware will happily and transparently use the Windows Hypervisor Platform (WHP, which is Hyper-V) for the under-the-hood virtualization.
Until you attempt to use a virtual machine that requires nested virtualization (eg a Windows VM with HVCI enabled). Thats when you'll realize that you can't do it. Ask me how I know. 😂
While Hyper-V does support nested virtualization, WHP does not, and I've heard of no plans to add support for it.
0
0
0
Will Dormann
wdormann@infosec.exchangeUpon further investigation, because that's how I am, I've confirmed that Hyper-V (on a completely different host system) behaves the same as VMware for me. The heap spray ends up at addresses to high to allow exploitation.
But for Stephen, both VMware- and Hyper-V-based ICS systems start heap spraying low enough to allow exploitation.
Neither one of us can figure out why this is the case.

 1
1
0
1
1
0
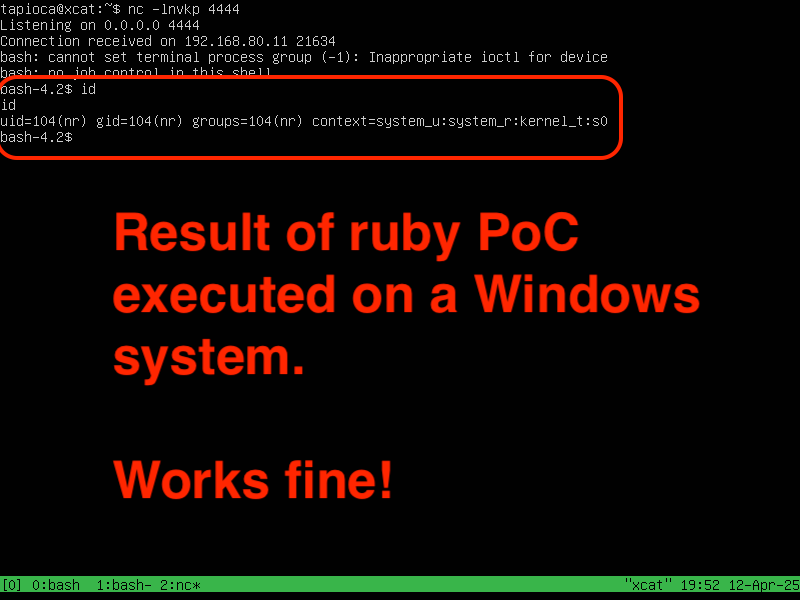
Will Dormann
wdormann@infosec.exchangeWell this is hilarious. When looking closer at Stephen's screenshot, I noticed that he was running Ruby from Windows. That couldn't make a difference, could it??
YES. If you run the PoC exploit from Windows, heap allocations will start at a low address and the exploit will work just fine. If you run the PoC exploit from Linux (I used Ubuntu), then the heap allocations will happen at a memory range that is too high to work.
I truly have less understanding of how computers work than I could ever have imagined.
Note that if you target an ICS system that has one CPU, you get one web process and ASLR will load libdsplibs.so at a different location every time. So you can guess a fixed address and it'll eventually be correct. But if your target ICS has multiple CPU cores, you'll get a fork()'d (but not exec()'d web process, so the memory layout will be the exact same every time. So the PoC would need to vary the guessed load address of libdsplibs.so for each attempt, rather than relying on the changes of the guess to happen server-side.
Edit: No, as per usual, I've fallen victim to another red herring here.

 2
1
0
2
1
0
Will Dormann
wdormann@infosec.exchange@catc0n
With some info from him and some troubleshooting on my end, I figured it out!
If you use Windows to run the Ruby PoC, it works! If you use Linux to run the Ruby PoC like a fool, it will not work because the allocations on the target side are too high to affect the exploit.
Because of course? 🤷♂️
https://infosec.exchange/@wdormann/114326756199092290
1
1
0


Will Dormann
wdormann@infosec.exchangeAs I dig deeper into this mystery, I've discovered that I'm (as expected) once again mistaken here.
Yes, the Rapid7 PoC needs Ruby 3.1 or older for it to work right.
But no, there isn't a difference between Linux Ruby and Windows Ruby here.
Why was I steered wrong?
Heap allocations on Linux (ICS) don't simply start at low addresses and grow higher. The allocations will use low addresses if they need to. Why didn't my allocations hit low addresses in all of my early testing? Because my ICS test systems all have multiple cores. Stephen's did not. Also, even in my single-core VMs, I suppose I didn't wait long enough before giving up after noticing that allocations were happening at high addresses. After seeing allocations happening at high addresses for a while, I incorrectly assumed that low addresses wouldn't be touched.
So if I were correcting this Rapid7 PoC, I would:
- Have the script itself modify the guessed
libdsplibs.sobase address. Because the Ivantiwebprocess does afork()without anexec(), every single re-spawnedwebprocess will have the exact same memory layout as its parent. As such, ASLR will only randomize anything in thewebprocess once at boot time, and not per time it crashes. - If the target is multi-core, then the heap spray will need to be larger. With the multi-
web-process situation you end up with on multi-core ICS systems, the default Rapid7 PoC will not work because any givenwebprocess will not get coerced into allocating at low addresses. - I'd probably update the script to work with modern Ruby versions. No need to crash upon attempting to figure out the target ICS version.
Just to help you all visualize what's going on here, here's a sped-up animation of the allocations happening in the web process when it receives the Rapid7 heap spray. Note that the low addresses aren't touched until near the end. My impatience to wait for the spray to complete led me to draw the incorrect conclusion that low addresses weren't going to get touched.
1
3
0
Will Dormann
wdormann@infosec.exchangeIf we want, we can tweak the Rapid7 PoC to work around these shortcomings.
While Stephen's PoC works quite well on single-core ICS systems, there's a problem with this: You're not going to see single-core ICS systems in the real world. Even bottom-of-the-line ancient physical PCS devices had 4-core CPUs. And Ivanti indicates that virtual deployments of ICS requires at least 2 CPUs.
What does this mean? The Rapid7 PoC will not work against real-world targets. (Which is why I questioned it earlier in this thread).
A single-core target is fine for testing the concept of the exploit. But until it works on multi-core targets, we can't assume that any ITW exploitation used a similar technique.
With a multi-core target, we have two primary differences that our PoC needs to account for:
- The heap spray needs to be larger, as multi-core ICS systems spawn multiple
webprocesses to dispatch incoming connections. - Due to how
webis designed, all respawnedwebprocesses will have the exact same memory layout as the long-lived parent process. As such, the PoC will need to guess different library addresses for each attempt.
With these tweaks, the PoC does work against a multi-core ICS target. However, I've noticed that the chance of a correctly-guessed-address exploit attempt drops from ~100% to something less than that.
So while a single-core target requires luck to be on your side for the libdsplibs.so in the newly-spawned web process to match your guess, you have the disadvantage of the possibility of being very unlucky. With a multi-core ICS target, however, you can guess all possible libdsplibs.so load addresses with 512 guesses, and one of them will be correct.
However, each of your attempts will involve a lot more traffic to the target. And, if you're lucky in your exploit attempt success rate, but unlucky in your guess of the libdsplibs.so address, you might end up sending 3TB of data to the ICS system before successfully exploiting it. If you're unlucky in both your exploit attempt success rate and your guess of the libdsplibs.so address, then the amount of data required to be sent to the target ICS system is perhaps unbounded.
In absence of a memory leak vulnerability, this exploitation technique is very noisy. Both in the repeated crashes of web in the system logs, and also the increased traffic to the ICS system as the results of the repeated heap sprays. But perhaps people don't really pay attention to these sorts of things. 😂
In the end, I'm quite curious as to what the ITW attempts actually looked like. But I suspect that even if Mandiant does know for sure, we'll probably never know...

 1
1
0
1
1
0
Will Dormann
wdormann@infosec.exchangeSince the update to patch April's CVE-2025-22457 was included in February's ICS updates (it didn't get CVE attention at that time as presumably Ivanti didn't recognize that stack buffer overflows are exploitable), the Ivanti Advisory indicated that the fix for CVE-2025-22457 could be downloaded from the Download Portal.
Because we are curious people, we read what vendors say. A few things jump out at me:
1) Despite there being existing CPEs for Ivanti Policy Secure (cpe:2.3:a:ivanti:policy_secure:...) and ZTA Gateways (cpe:2.3:a:ivanti:neurons_for_zero-trust_access:...), Ivanti chose either CPE in their advisory. I cannot fathom why.
Sub-wonder: For people using CPE in the real world, how do you know what CPE to use? I had to use ChatGPT to find the latter of the above, which seems... neither practical nor scalable? I'll admit that I know next to nothing about CPE other than inconsistently seeing them in CVE entries.
2) The patch availability for ZTA Gateways was April 19 and "will be automatically applied", and the availability for Ivanti Policy Secure is today (April 21). Might I conclude from this that all ZTA Gateways systems are protected, since April 19 has already passed? And that Ivanti Policy Secure systems have a patch available right now?
Ivanti hasn't updated their advisory since Apri 15.


 0
1
0
0
1
0